mirror of
https://github.com/infiniflow/ragflow.git
synced 2026-05-05 17:57:47 +08:00
docs: update docs icons (#12465)
### What problem does this PR solve? Update icons for docs. Trailing spaces are auto truncated by the editor, does not affect real content. ### Type of change - [x] Documentation Update
This commit is contained in:
@ -4,5 +4,8 @@
|
||||
"link": {
|
||||
"type": "generated-index",
|
||||
"description": "Guides for RAGFlow users and developers."
|
||||
},
|
||||
"customProps": {
|
||||
"sidebarIcon": "LucideBookMarked"
|
||||
}
|
||||
}
|
||||
|
||||
@ -4,5 +4,8 @@
|
||||
"link": {
|
||||
"type": "generated-index",
|
||||
"description": "RAGFlow administration"
|
||||
},
|
||||
"customProps": {
|
||||
"categoryIcon": "LucideUserCog"
|
||||
}
|
||||
}
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 2
|
||||
slug: /admin_cli
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideSquareTerminal
|
||||
}
|
||||
---
|
||||
|
||||
# Admin CLI
|
||||
@ -27,9 +30,9 @@ The RAGFlow Admin CLI is a command-line-based system administration tool that of
|
||||
The default password is admin.
|
||||
|
||||
**Parameters:**
|
||||
|
||||
|
||||
- -h: RAGFlow admin server host address
|
||||
|
||||
|
||||
- -p: RAGFlow admin server port
|
||||
|
||||
## Default administrative account
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 0
|
||||
slug: /admin_service
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideActivity
|
||||
}
|
||||
---
|
||||
|
||||
|
||||
@ -24,7 +27,7 @@ With its unified interface design, the Admin Service combines the convenience of
|
||||
python admin/server/admin_server.py
|
||||
```
|
||||
|
||||
The service will start and listen for incoming connections from the CLI on the configured port.
|
||||
The service will start and listen for incoming connections from the CLI on the configured port.
|
||||
|
||||
### Using docker image
|
||||
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 1
|
||||
slug: /admin_ui
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucidePalette
|
||||
}
|
||||
---
|
||||
|
||||
# Admin UI
|
||||
|
||||
@ -4,5 +4,8 @@
|
||||
"link": {
|
||||
"type": "generated-index",
|
||||
"description": "RAGFlow v0.8.0 introduces an agent mechanism, featuring a no-code workflow editor on the front end and a comprehensive graph-based task orchestration framework on the backend."
|
||||
},
|
||||
"customProps": {
|
||||
"categoryIcon": "RagAiAgent"
|
||||
}
|
||||
}
|
||||
|
||||
@ -4,5 +4,8 @@
|
||||
"link": {
|
||||
"type": "generated-index",
|
||||
"description": "A complete reference for RAGFlow's agent components."
|
||||
},
|
||||
"customProps": {
|
||||
"categoryIcon": "RagAiAgent"
|
||||
}
|
||||
}
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 2
|
||||
slug: /agent_component
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: RagAiAgent
|
||||
}
|
||||
---
|
||||
|
||||
# Agent component
|
||||
@ -16,7 +19,7 @@ An **Agent** component fine-tunes the LLM and sets its prompt. From v0.20.5 onwa
|
||||
|
||||
## Scenarios
|
||||
|
||||
An **Agent** component is essential when you need the LLM to assist with summarizing, translating, or controlling various tasks.
|
||||
An **Agent** component is essential when you need the LLM to assist with summarizing, translating, or controlling various tasks.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
@ -28,13 +31,13 @@ An **Agent** component is essential when you need the LLM to assist with summari
|
||||
|
||||
## Quickstart
|
||||
|
||||
### 1. Click on an **Agent** component to show its configuration panel
|
||||
### 1. Click on an **Agent** component to show its configuration panel
|
||||
|
||||
The corresponding configuration panel appears to the right of the canvas. Use this panel to define and fine-tune the **Agent** component's behavior.
|
||||
|
||||
### 2. Select your model
|
||||
|
||||
Click **Model**, and select a chat model from the dropdown menu.
|
||||
Click **Model**, and select a chat model from the dropdown menu.
|
||||
|
||||
:::tip NOTE
|
||||
If no model appears, check if your have added a chat model on the **Model providers** page.
|
||||
@ -55,7 +58,7 @@ In this quickstart, we assume your **Agent** component is used standalone (witho
|
||||
|
||||
### 5. Skip Tools and Agent
|
||||
|
||||
The **+ Add tools** and **+ Add agent** sections are used *only* when you need to configure your **Agent** component as a planner (with tools or sub-Agents beneath). In this quickstart, we assume your **Agent** component is used standalone (without tools or sub-Agents beneath).
|
||||
The **+ Add tools** and **+ Add agent** sections are used *only* when you need to configure your **Agent** component as a planner (with tools or sub-Agents beneath). In this quickstart, we assume your **Agent** component is used standalone (without tools or sub-Agents beneath).
|
||||
|
||||
### 6. Choose the next component
|
||||
|
||||
@ -71,7 +74,7 @@ In this section, we assume your **Agent** will be configured as a planner, with
|
||||
|
||||

|
||||
|
||||
### 2. Configure your Tavily MCP server
|
||||
### 2. Configure your Tavily MCP server
|
||||
|
||||
Update your MCP server's name, URL (including the API key), server type, and other necessary settings. When configured correctly, the available tools will be displayed.
|
||||
|
||||
@ -110,7 +113,7 @@ On the canvas, click the newly-populated Tavily server to view and select its av
|
||||
|
||||
Click the dropdown menu of **Model** to show the model configuration window.
|
||||
|
||||
- **Model**: The chat model to use.
|
||||
- **Model**: The chat model to use.
|
||||
- Ensure you set the chat model correctly on the **Model providers** page.
|
||||
- You can use different models for different components to increase flexibility or improve overall performance.
|
||||
- **Creativity**: A shortcut to **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty** settings, indicating the freedom level of the model. From **Improvise**, **Precise**, to **Balance**, each preset configuration corresponds to a unique combination of **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty**.
|
||||
@ -118,21 +121,21 @@ Click the dropdown menu of **Model** to show the model configuration window.
|
||||
- **Improvise**: Produces more creative responses.
|
||||
- **Precise**: (Default) Produces more conservative responses.
|
||||
- **Balance**: A middle ground between **Improvise** and **Precise**.
|
||||
- **Temperature**: The randomness level of the model's output.
|
||||
- **Temperature**: The randomness level of the model's output.
|
||||
Defaults to 0.1.
|
||||
- Lower values lead to more deterministic and predictable outputs.
|
||||
- Higher values lead to more creative and varied outputs.
|
||||
- A temperature of zero results in the same output for the same prompt.
|
||||
- **Top P**: Nucleus sampling.
|
||||
- **Top P**: Nucleus sampling.
|
||||
- Reduces the likelihood of generating repetitive or unnatural text by setting a threshold *P* and restricting the sampling to tokens with a cumulative probability exceeding *P*.
|
||||
- Defaults to 0.3.
|
||||
- **Presence penalty**: Encourages the model to include a more diverse range of tokens in the response.
|
||||
- **Presence penalty**: Encourages the model to include a more diverse range of tokens in the response.
|
||||
- A higher **presence penalty** value results in the model being more likely to generate tokens not yet been included in the generated text.
|
||||
- Defaults to 0.4.
|
||||
- **Frequency penalty**: Discourages the model from repeating the same words or phrases too frequently in the generated text.
|
||||
- **Frequency penalty**: Discourages the model from repeating the same words or phrases too frequently in the generated text.
|
||||
- A higher **frequency penalty** value results in the model being more conservative in its use of repeated tokens.
|
||||
- Defaults to 0.7.
|
||||
- **Max tokens**:
|
||||
- **Max tokens**:
|
||||
This sets the maximum length of the model's output, measured in the number of tokens (words or pieces of words). It is disabled by default, allowing the model to determine the number of tokens in its responses.
|
||||
|
||||
:::tip NOTE
|
||||
@ -142,7 +145,7 @@ Click the dropdown menu of **Model** to show the model configuration window.
|
||||
|
||||
### System prompt
|
||||
|
||||
Typically, you use the system prompt to describe the task for the LLM, specify how it should respond, and outline other miscellaneous requirements. We do not plan to elaborate on this topic, as it can be as extensive as prompt engineering. However, please be aware that the system prompt is often used in conjunction with keys (variables), which serve as various data inputs for the LLM.
|
||||
Typically, you use the system prompt to describe the task for the LLM, specify how it should respond, and outline other miscellaneous requirements. We do not plan to elaborate on this topic, as it can be as extensive as prompt engineering. However, please be aware that the system prompt is often used in conjunction with keys (variables), which serve as various data inputs for the LLM.
|
||||
|
||||
An **Agent** component relies on keys (variables) to specify its data inputs. Its immediate upstream component is *not* necessarily its data input, and the arrows in the workflow indicate *only* the processing sequence. Keys in a **Agent** component are used in conjunction with the system prompt to specify data inputs for the LLM. Use a forward slash `/` or the **(x)** button to show the keys to use.
|
||||
|
||||
@ -190,11 +193,11 @@ From v0.20.5 onwards, four framework-level prompt blocks are available in the **
|
||||
The user-defined prompt. Defaults to `sys.query`, the user query. As a general rule, when using the **Agent** component as a standalone module (not as a planner), you usually need to specify the corresponding **Retrieval** component’s output variable (`formalized_content`) here as part of the input to the LLM.
|
||||
|
||||
|
||||
### Tools
|
||||
### Tools
|
||||
|
||||
You can use an **Agent** component as a collaborator that reasons and reflects with the aid of other tools; for instance, **Retrieval** can serve as one such tool for an **Agent**.
|
||||
|
||||
### Agent
|
||||
### Agent
|
||||
|
||||
You use an **Agent** component as a collaborator that reasons and reflects with the aid of subagents or other tools, forming a multi-agent system.
|
||||
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 5
|
||||
slug: /await_response
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideMessageSquareDot
|
||||
}
|
||||
---
|
||||
|
||||
# Await response component
|
||||
@ -23,7 +26,7 @@ Whether to show the message defined in the **Message** field.
|
||||
|
||||
### Message
|
||||
|
||||
The static message to send out.
|
||||
The static message to send out.
|
||||
|
||||
Click **+ Add message** to add message options. When multiple messages are supplied, the **Message** component randomly selects one to send.
|
||||
|
||||
@ -31,9 +34,9 @@ Click **+ Add message** to add message options. When multiple messages are suppl
|
||||
|
||||
You can define global variables within the **Await response** component, which can be either mandatory or optional. Once set, users will need to provide values for these variables when engaging with the agent. Click **+** to add a global variable, each with the following attributes:
|
||||
|
||||
- **Name**: _Required_
|
||||
A descriptive name providing additional details about the variable.
|
||||
- **Type**: _Required_
|
||||
- **Name**: _Required_
|
||||
A descriptive name providing additional details about the variable.
|
||||
- **Type**: _Required_
|
||||
The type of the variable:
|
||||
- **Single-line text**: Accepts a single line of text without line breaks.
|
||||
- **Paragraph text**: Accepts multiple lines of text, including line breaks.
|
||||
@ -41,7 +44,7 @@ You can define global variables within the **Await response** component, which c
|
||||
- **file upload**: Requires the user to upload one or multiple files.
|
||||
- **Number**: Accepts a number as input.
|
||||
- **Boolean**: Requires the user to toggle between on and off.
|
||||
- **Key**: _Required_
|
||||
- **Key**: _Required_
|
||||
The unique variable name.
|
||||
- **Optional**: A toggle indicating whether the variable is optional.
|
||||
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 1
|
||||
slug: /begin_component
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideHome
|
||||
}
|
||||
---
|
||||
|
||||
# Begin component
|
||||
@ -36,9 +39,9 @@ An agent in conversational mode begins with an opening greeting. It is the agent
|
||||
|
||||
You can define global variables within the **Begin** component, which can be either mandatory or optional. Once set, users will need to provide values for these variables when engaging with the agent. Click **+ Add variable** to add a global variable, each with the following attributes:
|
||||
|
||||
- **Name**: _Required_
|
||||
A descriptive name providing additional details about the variable.
|
||||
- **Type**: _Required_
|
||||
- **Name**: _Required_
|
||||
A descriptive name providing additional details about the variable.
|
||||
- **Type**: _Required_
|
||||
The type of the variable:
|
||||
- **Single-line text**: Accepts a single line of text without line breaks.
|
||||
- **Paragraph text**: Accepts multiple lines of text, including line breaks.
|
||||
@ -46,7 +49,7 @@ You can define global variables within the **Begin** component, which can be eit
|
||||
- **file upload**: Requires the user to upload one or multiple files.
|
||||
- **Number**: Accepts a number as input.
|
||||
- **Boolean**: Requires the user to toggle between on and off.
|
||||
- **Key**: _Required_
|
||||
- **Key**: _Required_
|
||||
The unique variable name.
|
||||
- **Optional**: A toggle indicating whether the variable is optional.
|
||||
|
||||
|
||||
@ -1,11 +1,14 @@
|
||||
---
|
||||
sidebar_position: 8
|
||||
slug: /categorize_component
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideSwatchBook
|
||||
}
|
||||
---
|
||||
|
||||
# Categorize component
|
||||
|
||||
A component that classifies user inputs and applies strategies accordingly.
|
||||
A component that classifies user inputs and applies strategies accordingly.
|
||||
|
||||
---
|
||||
|
||||
@ -23,7 +26,7 @@ A **Categorize** component is essential when you need the LLM to help you identi
|
||||
|
||||
Select the source for categorization.
|
||||
|
||||
The **Categorize** component relies on query variables to specify its data inputs (queries). All global variables defined before the **Categorize** component are available in the dropdown list.
|
||||
The **Categorize** component relies on query variables to specify its data inputs (queries). All global variables defined before the **Categorize** component are available in the dropdown list.
|
||||
|
||||
|
||||
### Input
|
||||
@ -31,7 +34,7 @@ The **Categorize** component relies on query variables to specify its data input
|
||||
The **Categorize** component relies on input variables to specify its data inputs (queries). Click **+ Add variable** in the **Input** section to add the desired input variables. There are two types of input variables: **Reference** and **Text**.
|
||||
|
||||
- **Reference**: Uses a component's output or a user input as the data source. You are required to select from the dropdown menu:
|
||||
- A component ID under **Component Output**, or
|
||||
- A component ID under **Component Output**, or
|
||||
- A global variable under **Begin input**, which is defined in the **Begin** component.
|
||||
- **Text**: Uses fixed text as the query. You are required to enter static text.
|
||||
|
||||
@ -39,29 +42,29 @@ The **Categorize** component relies on input variables to specify its data input
|
||||
|
||||
Click the dropdown menu of **Model** to show the model configuration window.
|
||||
|
||||
- **Model**: The chat model to use.
|
||||
- **Model**: The chat model to use.
|
||||
- Ensure you set the chat model correctly on the **Model providers** page.
|
||||
- You can use different models for different components to increase flexibility or improve overall performance.
|
||||
- **Creativity**: A shortcut to **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty** settings, indicating the freedom level of the model. From **Improvise**, **Precise**, to **Balance**, each preset configuration corresponds to a unique combination of **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty**.
|
||||
This parameter has three options:
|
||||
This parameter has three options:
|
||||
- **Improvise**: Produces more creative responses.
|
||||
- **Precise**: (Default) Produces more conservative responses.
|
||||
- **Balance**: A middle ground between **Improvise** and **Precise**.
|
||||
- **Temperature**: The randomness level of the model's output.
|
||||
Defaults to 0.1.
|
||||
- **Temperature**: The randomness level of the model's output.
|
||||
Defaults to 0.1.
|
||||
- Lower values lead to more deterministic and predictable outputs.
|
||||
- Higher values lead to more creative and varied outputs.
|
||||
- A temperature of zero results in the same output for the same prompt.
|
||||
- **Top P**: Nucleus sampling.
|
||||
- **Top P**: Nucleus sampling.
|
||||
- Reduces the likelihood of generating repetitive or unnatural text by setting a threshold *P* and restricting the sampling to tokens with a cumulative probability exceeding *P*.
|
||||
- Defaults to 0.3.
|
||||
- **Presence penalty**: Encourages the model to include a more diverse range of tokens in the response.
|
||||
- **Presence penalty**: Encourages the model to include a more diverse range of tokens in the response.
|
||||
- A higher **presence penalty** value results in the model being more likely to generate tokens not yet been included in the generated text.
|
||||
- Defaults to 0.4.
|
||||
- **Frequency penalty**: Discourages the model from repeating the same words or phrases too frequently in the generated text.
|
||||
- **Frequency penalty**: Discourages the model from repeating the same words or phrases too frequently in the generated text.
|
||||
- A higher **frequency penalty** value results in the model being more conservative in its use of repeated tokens.
|
||||
- Defaults to 0.7.
|
||||
- **Max tokens**:
|
||||
- **Max tokens**:
|
||||
This sets the maximum length of the model's output, measured in the number of tokens (words or pieces of words). It is disabled by default, allowing the model to determine the number of tokens in its responses.
|
||||
|
||||
:::tip NOTE
|
||||
@ -81,7 +84,7 @@ This feature is used for multi-turn dialogue *only*. If your **Categorize** comp
|
||||
|
||||
### Category name
|
||||
|
||||
A **Categorize** component must have at least two categories. This field sets the name of the category. Click **+ Add Item** to include the intended categories.
|
||||
A **Categorize** component must have at least two categories. This field sets the name of the category. Click **+ Add Item** to include the intended categories.
|
||||
|
||||
:::tip NOTE
|
||||
You will notice that the category name is auto-populated. No worries. Each category is assigned a random name upon creation. Feel free to change it to a name that is understandable to the LLM.
|
||||
@ -89,7 +92,7 @@ You will notice that the category name is auto-populated. No worries. Each categ
|
||||
|
||||
#### Description
|
||||
|
||||
Description of this category.
|
||||
Description of this category.
|
||||
|
||||
You can input criteria, situation, or information that may help the LLM determine which inputs belong in this category.
|
||||
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 31
|
||||
slug: /chunker_title_component
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideBlocks
|
||||
}
|
||||
---
|
||||
|
||||
# Title chunker component
|
||||
@ -23,7 +26,7 @@ Placing a **Title chunker** after a **Token chunker** is invalid and will cause
|
||||
|
||||
### Hierarchy
|
||||
|
||||
Specifies the heading level to define chunk boundaries:
|
||||
Specifies the heading level to define chunk boundaries:
|
||||
|
||||
- H1
|
||||
- H2
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 32
|
||||
slug: /chunker_token_component
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideBlocks
|
||||
}
|
||||
---
|
||||
|
||||
# Token chunker component
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 13
|
||||
slug: /code_component
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideCodeXml
|
||||
}
|
||||
---
|
||||
|
||||
# Code component
|
||||
@ -33,7 +36,7 @@ If your RAGFlow Sandbox is not working, please be sure to consult the [Troublesh
|
||||
|
||||
### 3. (Optional) Install necessary dependencies
|
||||
|
||||
If you need to import your own Python or JavaScript packages into Sandbox, please follow the commands provided in the [How to import my own Python or JavaScript packages into Sandbox?](#how-to-import-my-own-python-or-javascript-packages-into-sandbox) section to install the additional dependencies.
|
||||
If you need to import your own Python or JavaScript packages into Sandbox, please follow the commands provided in the [How to import my own Python or JavaScript packages into Sandbox?](#how-to-import-my-own-python-or-javascript-packages-into-sandbox) section to install the additional dependencies.
|
||||
|
||||
### 4. Enable Sandbox-specific settings in RAGFlow
|
||||
|
||||
@ -43,11 +46,11 @@ Ensure all Sandbox-specific settings are enabled in **ragflow/docker/.env**.
|
||||
|
||||
Any changes to the configuration or environment *require* a full service restart to take effect.
|
||||
|
||||
## Configurations
|
||||
## Configurations
|
||||
|
||||
### Input
|
||||
|
||||
You can specify multiple input sources for the **Code** component. Click **+ Add variable** in the **Input variables** section to include the desired input variables.
|
||||
You can specify multiple input sources for the **Code** component. Click **+ Add variable** in the **Input variables** section to include the desired input variables.
|
||||
|
||||
### Code
|
||||
|
||||
@ -59,7 +62,7 @@ If your code implementation includes defined variables, whether input or output
|
||||
|
||||
#### A Python code example
|
||||
|
||||
```Python
|
||||
```Python
|
||||
def main(arg1: str, arg2: str) -> dict:
|
||||
return {
|
||||
"result": arg1 + arg2,
|
||||
@ -102,7 +105,7 @@ The defined output variable(s) will be auto-populated here.
|
||||
|
||||
### `HTTPConnectionPool(host='sandbox-executor-manager', port=9385): Read timed out.`
|
||||
|
||||
**Root cause**
|
||||
**Root cause**
|
||||
|
||||
- You did not properly install gVisor and `runsc` was not recognized as a valid Docker runtime.
|
||||
- You did not pull the required base images for the runners and no runner was started.
|
||||
@ -144,11 +147,11 @@ docker build -t sandbox-executor-manager:latest ./sandbox/executor_manager
|
||||
|
||||
### `HTTPConnectionPool(host='none', port=9385): Max retries exceeded.`
|
||||
|
||||
**Root cause**
|
||||
**Root cause**
|
||||
|
||||
`sandbox-executor-manager` is not mapped in `/etc/hosts`.
|
||||
|
||||
**Solution**
|
||||
**Solution**
|
||||
|
||||
Add a new entry to `/etc/hosts`:
|
||||
|
||||
@ -156,11 +159,11 @@ Add a new entry to `/etc/hosts`:
|
||||
|
||||
### `Container pool is busy`
|
||||
|
||||
**Root cause**
|
||||
**Root cause**
|
||||
|
||||
All runners are currently in use, executing tasks.
|
||||
All runners are currently in use, executing tasks.
|
||||
|
||||
**Solution**
|
||||
**Solution**
|
||||
|
||||
Please try again shortly or increase the pool size in the configuration to improve availability and reduce waiting times.
|
||||
|
||||
@ -205,7 +208,7 @@ To import your JavaScript packages, navigate to `sandbox_base_image/nodejs` and
|
||||
|
||||
(ragflow) ➜ ragflow/sandbox main ✓ cd sandbox_base_image/nodejs
|
||||
|
||||
(ragflow) ➜ ragflow/sandbox/sandbox_base_image/nodejs main ✓ npm install lodash
|
||||
(ragflow) ➜ ragflow/sandbox/sandbox_base_image/nodejs main ✓ npm install lodash
|
||||
|
||||
(ragflow) ➜ ragflow/sandbox/sandbox_base_image/nodejs main ✓ cd ../.. # go back to sandbox root directory
|
||||
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 25
|
||||
slug: /execute_sql
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: RagSql
|
||||
}
|
||||
---
|
||||
|
||||
# Execute SQL tool
|
||||
@ -9,7 +12,7 @@ A tool that execute SQL queries on a specified relational database.
|
||||
|
||||
---
|
||||
|
||||
The **Execute SQL** tool enables you to connect to a relational database and run SQL queries, whether entered directly or generated by the system’s Text2SQL capability via an **Agent** component.
|
||||
The **Execute SQL** tool enables you to connect to a relational database and run SQL queries, whether entered directly or generated by the system’s Text2SQL capability via an **Agent** component.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
|
||||
@ -1,11 +1,14 @@
|
||||
---
|
||||
sidebar_position: 30
|
||||
slug: /http_request_component
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: RagHTTP
|
||||
}
|
||||
---
|
||||
|
||||
# HTTP request component
|
||||
|
||||
A component that calls remote services.
|
||||
A component that calls remote services.
|
||||
|
||||
---
|
||||
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 40
|
||||
slug: /indexer_component
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideListPlus
|
||||
}
|
||||
---
|
||||
|
||||
# Indexer component
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 7
|
||||
slug: /iteration_component
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideRepeat2
|
||||
}
|
||||
---
|
||||
|
||||
# Iteration component
|
||||
@ -9,12 +12,12 @@ A component that splits text input into text segments and iterates a predefined
|
||||
|
||||
---
|
||||
|
||||
An **Interaction** component can divide text input into text segments and apply its built-in component workflow to each segment.
|
||||
An **Interaction** component can divide text input into text segments and apply its built-in component workflow to each segment.
|
||||
|
||||
|
||||
## Scenario
|
||||
|
||||
An **Iteration** component is essential when a workflow loop is required and the loop count is *not* fixed but depends on number of segments created from the output of specific agent components.
|
||||
An **Iteration** component is essential when a workflow loop is required and the loop count is *not* fixed but depends on number of segments created from the output of specific agent components.
|
||||
|
||||
- If, for instance, you plan to feed several paragraphs into an LLM for content generation, each with its own focus, and feeding them to the LLM all at once could create confusion or contradictions, then you can use an **Iteration** component, which encapsulates a **Generate** component, to repeat the content generation process for each paragraph.
|
||||
- Another example: If you wish to use the LLM to translate a lengthy paper into a target language without exceeding its token limit, consider using an **Iteration** component, which encapsulates a **Generate** component, to break the paper into smaller pieces and repeat the translation process for each one.
|
||||
@ -29,12 +32,12 @@ Each **Iteration** component includes an internal **IterationItem** component. T
|
||||
The **IterationItem** component is visible *only* to the components encapsulated by the current **Iteration** components.
|
||||
:::
|
||||
|
||||
### Build an internal workflow
|
||||
### Build an internal workflow
|
||||
|
||||
You are allowed to pull other components into the **Iteration** component to build an internal workflow, and these "added internal components" are no longer visible to components outside of the current **Iteration** component.
|
||||
|
||||
:::danger IMPORTANT
|
||||
To reference the created text segments from an added internal component, simply add a **Reference** variable that equals **IterationItem** within the **Input** section of that internal component. There is no need to reference the corresponding external component, as the **IterationItem** component manages the loop of the workflow for all created text segments.
|
||||
To reference the created text segments from an added internal component, simply add a **Reference** variable that equals **IterationItem** within the **Input** section of that internal component. There is no need to reference the corresponding external component, as the **IterationItem** component manages the loop of the workflow for all created text segments.
|
||||
:::
|
||||
|
||||
:::tip NOTE
|
||||
@ -48,7 +51,7 @@ An added internal component can reference an external component when necessary.
|
||||
The **Iteration** component uses input variables to specify its data inputs, namely the texts to be segmented. You are allowed to specify multiple input sources for the **Iteration** component. Click **+ Add variable** in the **Input** section to include the desired input variables. There are two types of input variables: **Reference** and **Text**.
|
||||
|
||||
- **Reference**: Uses a component's output or a user input as the data source. You are required to select from the dropdown menu:
|
||||
- A component ID under **Component Output**, or
|
||||
- A component ID under **Component Output**, or
|
||||
- A global variable under **Begin input**, which is defined in the **Begin** component.
|
||||
- **Text**: Uses fixed text as the query. You are required to enter static text.
|
||||
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 4
|
||||
slug: /message_component
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideMessageSquareReply
|
||||
}
|
||||
---
|
||||
|
||||
# Message component
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 30
|
||||
slug: /parser_component
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideFilePlay
|
||||
}
|
||||
---
|
||||
|
||||
# Parser component
|
||||
@ -54,12 +57,12 @@ Starting from v0.22.0, RAGFlow includes MinerU (≥ 2.6.3) as an optional PDF p
|
||||
- `"vlm-mlx-engine"`
|
||||
- `"vlm-vllm-async-engine"`
|
||||
- `"vlm-lmdeploy-engine"`.
|
||||
- `MINERU_SERVER_URL`: (optional) The downstream vLLM HTTP server (e.g., `http://vllm-host:30000`). Applicable when `MINERU_BACKEND` is set to `"vlm-http-client"`.
|
||||
- `MINERU_SERVER_URL`: (optional) The downstream vLLM HTTP server (e.g., `http://vllm-host:30000`). Applicable when `MINERU_BACKEND` is set to `"vlm-http-client"`.
|
||||
- `MINERU_OUTPUT_DIR`: (optional) The local directory for holding the outputs of the MinerU API service (zip/JSON) before ingestion.
|
||||
- `MINERU_DELETE_OUTPUT`: Whether to delete temporary output when a temporary directory is used:
|
||||
- `1`: Delete.
|
||||
- `0`: Retain.
|
||||
3. In the web UI, navigate to your dataset's **Configuration** page and find the **Ingestion pipeline** section:
|
||||
3. In the web UI, navigate to your dataset's **Configuration** page and find the **Ingestion pipeline** section:
|
||||
- If you decide to use a chunking method from the **Built-in** dropdown, ensure it supports PDF parsing, then select **MinerU** from the **PDF parser** dropdown.
|
||||
- If you use a custom ingestion pipeline instead, select **MinerU** in the **PDF parser** section of the **Parser** component.
|
||||
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 3
|
||||
slug: /retrieval_component
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideFolderSearch
|
||||
}
|
||||
---
|
||||
|
||||
# Retrieval component
|
||||
@ -21,13 +24,13 @@ Ensure you [have properly configured your target dataset(s)](../../dataset/confi
|
||||
|
||||
## Quickstart
|
||||
|
||||
### 1. Click on a **Retrieval** component to show its configuration panel
|
||||
### 1. Click on a **Retrieval** component to show its configuration panel
|
||||
|
||||
The corresponding configuration panel appears to the right of the canvas. Use this panel to define and fine-tune the **Retrieval** component's search behavior.
|
||||
|
||||
### 2. Input query variable(s)
|
||||
|
||||
The **Retrieval** component depends on query variables to specify its queries.
|
||||
The **Retrieval** component depends on query variables to specify its queries.
|
||||
|
||||
:::caution IMPORTANT
|
||||
- If you use the **Retrieval** component as a standalone workflow module, input query variables in the **Input Variables** text box.
|
||||
@ -74,7 +77,7 @@ Select the query source for retrieval. Defaults to `sys.query`, which is the def
|
||||
|
||||
The **Retrieval** component relies on query variables to specify its queries. All global variables defined before the **Retrieval** component can also be used as queries. Use the `(x)` button or type `/` to show all the available query variables.
|
||||
|
||||
### Knowledge bases
|
||||
### Knowledge bases
|
||||
|
||||
Select the dataset(s) to retrieve data from.
|
||||
|
||||
@ -110,7 +113,7 @@ Using a rerank model will *significantly* increase the system's response time.
|
||||
|
||||
### Empty response
|
||||
|
||||
- Set this as a response if no results are retrieved from the dataset(s) for your query, or
|
||||
- Set this as a response if no results are retrieved from the dataset(s) for your query, or
|
||||
- Leave this field blank to allow the chat model to improvise when nothing is found.
|
||||
|
||||
:::caution WARNING
|
||||
|
||||
@ -1,11 +1,14 @@
|
||||
---
|
||||
sidebar_position: 6
|
||||
slug: /switch_component
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideSplit
|
||||
}
|
||||
---
|
||||
|
||||
# Switch component
|
||||
|
||||
A component that evaluates whether specified conditions are met and directs the follow of execution accordingly.
|
||||
A component that evaluates whether specified conditions are met and directs the follow of execution accordingly.
|
||||
|
||||
---
|
||||
|
||||
@ -13,7 +16,7 @@ A **Switch** component evaluates conditions based on the output of specific comp
|
||||
|
||||
## Scenarios
|
||||
|
||||
A **Switch** component is essential for condition-based direction of execution flow. While it shares similarities with the [Categorize](./categorize.mdx) component, which is also used in multi-pronged strategies, the key distinction lies in their approach: the evaluation of the **Switch** component is rule-based, whereas the **Categorize** component involves AI and uses an LLM for decision-making.
|
||||
A **Switch** component is essential for condition-based direction of execution flow. While it shares similarities with the [Categorize](./categorize.mdx) component, which is also used in multi-pronged strategies, the key distinction lies in their approach: the evaluation of the **Switch** component is rule-based, whereas the **Categorize** component involves AI and uses an LLM for decision-making.
|
||||
|
||||
## Configurations
|
||||
|
||||
@ -39,12 +42,12 @@ When you have added multiple conditions for a specific case, a **Logical operato
|
||||
- Greater equal
|
||||
- Less than
|
||||
- Less equal
|
||||
- Contains
|
||||
- Not contains
|
||||
- Contains
|
||||
- Not contains
|
||||
- Starts with
|
||||
- Ends with
|
||||
- Is empty
|
||||
- Not empty
|
||||
- **Value**: A single value, which can be an integer, float, or string.
|
||||
- **Value**: A single value, which can be an integer, float, or string.
|
||||
- Delimiters, multiple values, or expressions are *not* supported.
|
||||
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 15
|
||||
slug: /text_processing
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideType
|
||||
}
|
||||
---
|
||||
|
||||
# Text processing component
|
||||
@ -24,7 +27,7 @@ Appears only when you select **Split** as method.
|
||||
|
||||
The variable to be split. Type `/` to quickly insert variables.
|
||||
|
||||
### Script
|
||||
### Script
|
||||
|
||||
Template for the merge. Appears only when you select **Merge** as method. Type `/` to quickly insert variables.
|
||||
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 37
|
||||
slug: /transformer_component
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideFileStack
|
||||
}
|
||||
---
|
||||
|
||||
# Transformer component
|
||||
@ -13,7 +16,7 @@ A **Transformer** component indexes chunks and configures their storage formats
|
||||
|
||||
## Scenario
|
||||
|
||||
A **Transformer** component is essential when you need the LLM to extract new information, such as keywords, questions, metadata, and summaries, from the original chunks.
|
||||
A **Transformer** component is essential when you need the LLM to extract new information, such as keywords, questions, metadata, and summaries, from the original chunks.
|
||||
|
||||
## Configurations
|
||||
|
||||
@ -21,29 +24,29 @@ A **Transformer** component is essential when you need the LLM to extract new in
|
||||
|
||||
Click the dropdown menu of **Model** to show the model configuration window.
|
||||
|
||||
- **Model**: The chat model to use.
|
||||
- **Model**: The chat model to use.
|
||||
- Ensure you set the chat model correctly on the **Model providers** page.
|
||||
- You can use different models for different components to increase flexibility or improve overall performance.
|
||||
- **Creativity**: A shortcut to **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty** settings, indicating the freedom level of the model. From **Improvise**, **Precise**, to **Balance**, each preset configuration corresponds to a unique combination of **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty**.
|
||||
- **Creativity**: A shortcut to **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty** settings, indicating the freedom level of the model. From **Improvise**, **Precise**, to **Balance**, each preset configuration corresponds to a unique combination of **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty**.
|
||||
This parameter has three options:
|
||||
- **Improvise**: Produces more creative responses.
|
||||
- **Precise**: (Default) Produces more conservative responses.
|
||||
- **Balance**: A middle ground between **Improvise** and **Precise**.
|
||||
- **Temperature**: The randomness level of the model's output.
|
||||
- **Temperature**: The randomness level of the model's output.
|
||||
Defaults to 0.1.
|
||||
- Lower values lead to more deterministic and predictable outputs.
|
||||
- Higher values lead to more creative and varied outputs.
|
||||
- A temperature of zero results in the same output for the same prompt.
|
||||
- **Top P**: Nucleus sampling.
|
||||
- **Top P**: Nucleus sampling.
|
||||
- Reduces the likelihood of generating repetitive or unnatural text by setting a threshold *P* and restricting the sampling to tokens with a cumulative probability exceeding *P*.
|
||||
- Defaults to 0.3.
|
||||
- **Presence penalty**: Encourages the model to include a more diverse range of tokens in the response.
|
||||
- **Presence penalty**: Encourages the model to include a more diverse range of tokens in the response.
|
||||
- A higher **presence penalty** value results in the model being more likely to generate tokens not yet been included in the generated text.
|
||||
- Defaults to 0.4.
|
||||
- **Frequency penalty**: Discourages the model from repeating the same words or phrases too frequently in the generated text.
|
||||
- **Frequency penalty**: Discourages the model from repeating the same words or phrases too frequently in the generated text.
|
||||
- A higher **frequency penalty** value results in the model being more conservative in its use of repeated tokens.
|
||||
- Defaults to 0.7.
|
||||
- **Max tokens**:
|
||||
- **Max tokens**:
|
||||
This sets the maximum length of the model's output, measured in the number of tokens (words or pieces of words). It is disabled by default, allowing the model to determine the number of tokens in its responses.
|
||||
|
||||
:::tip NOTE
|
||||
@ -62,7 +65,7 @@ Select the type of output to be generated by the LLM:
|
||||
|
||||
### System prompt
|
||||
|
||||
Typically, you use the system prompt to describe the task for the LLM, specify how it should respond, and outline other miscellaneous requirements. We do not plan to elaborate on this topic, as it can be as extensive as prompt engineering.
|
||||
Typically, you use the system prompt to describe the task for the LLM, specify how it should respond, and outline other miscellaneous requirements. We do not plan to elaborate on this topic, as it can be as extensive as prompt engineering.
|
||||
|
||||
:::tip NOTE
|
||||
The system prompt here automatically updates to match your selected **Result destination**.
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 1
|
||||
slug: /agent_introduction
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideBookOpenText
|
||||
}
|
||||
---
|
||||
|
||||
# Introduction to agents
|
||||
@ -24,7 +27,7 @@ Agents and RAG are complementary techniques, each enhancing the other’s capabi
|
||||
|
||||
:::tip NOTE
|
||||
|
||||
Before proceeding, ensure that:
|
||||
Before proceeding, ensure that:
|
||||
|
||||
1. You have properly set the LLM to use. See the guides on [Configure your API key](../models/llm_api_key_setup.md) or [Deploy a local LLM](../models/deploy_local_llm.mdx) for more information.
|
||||
2. You have a dataset configured and the corresponding files properly parsed. See the guide on [Configure a dataset](../dataset/configure_knowledge_base.md) for more information.
|
||||
@ -41,7 +44,7 @@ We also provide templates catered to different business scenarios. You can eithe
|
||||
|
||||
|
||||
|
||||
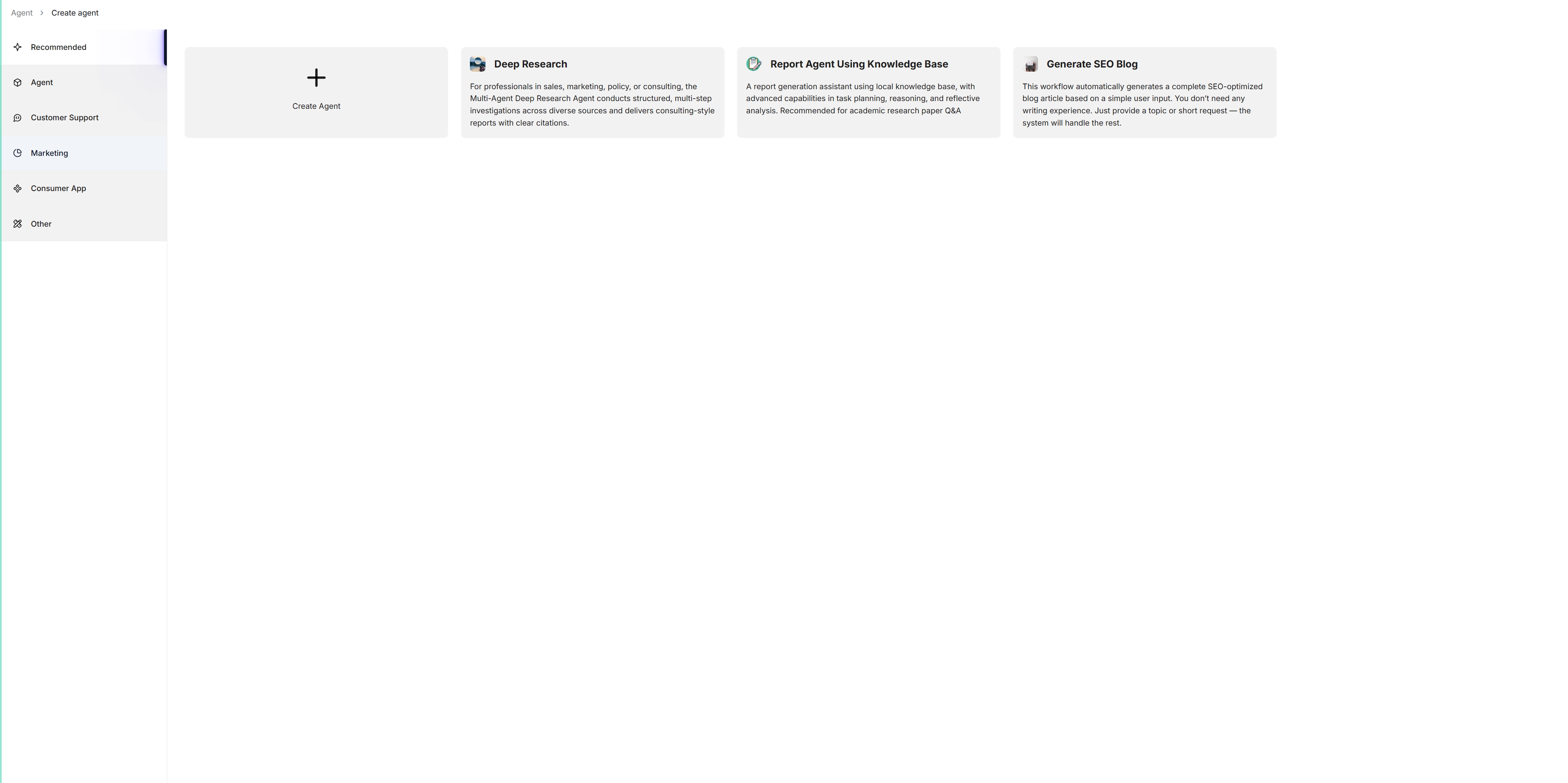
2. To create an agent from scratch, click **Create Agent**. Alternatively, to create an agent from one of our templates, click the desired card, such as **Deep Research**, name your agent in the pop-up dialogue, and click **OK** to confirm.
|
||||
2. To create an agent from scratch, click **Create Agent**. Alternatively, to create an agent from one of our templates, click the desired card, such as **Deep Research**, name your agent in the pop-up dialogue, and click **OK** to confirm.
|
||||
|
||||
*You are now taken to the **no-code workflow editor** page.*
|
||||
|
||||
|
||||
@ -4,5 +4,8 @@
|
||||
"link": {
|
||||
"type": "generated-index",
|
||||
"description": "Best practices on Agent configuration."
|
||||
},
|
||||
"customProps": {
|
||||
"categoryIcon": "LucideStar"
|
||||
}
|
||||
}
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 3
|
||||
slug: /embed_agent_into_webpage
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideMonitorDot
|
||||
}
|
||||
---
|
||||
|
||||
# Embed agent into webpage
|
||||
|
||||
@ -1,13 +1,16 @@
|
||||
---
|
||||
sidebar_position: 20
|
||||
slug: /sandbox_quickstart
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideCodesandbox
|
||||
}
|
||||
---
|
||||
|
||||
# Sandbox quickstart
|
||||
|
||||
A secure, pluggable code execution backend designed for RAGFlow and other applications requiring isolated code execution environments.
|
||||
|
||||
## Features:
|
||||
## Features:
|
||||
|
||||
- Seamless RAGFlow Integration — Works out-of-the-box with the code component of RAGFlow.
|
||||
- High Security — Uses gVisor for syscall-level sandboxing to isolate execution.
|
||||
@ -55,7 +58,7 @@ Next, build the executor manager image:
|
||||
docker build -t sandbox-executor-manager:latest ./executor_manager
|
||||
```
|
||||
|
||||
## Running with RAGFlow
|
||||
## Running with RAGFlow
|
||||
|
||||
1. Verify that gVisor is properly installed and operational.
|
||||
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 2
|
||||
slug: /ai_search
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideSearch
|
||||
}
|
||||
---
|
||||
|
||||
# Search
|
||||
@ -9,7 +12,7 @@ Conduct an AI search.
|
||||
|
||||
---
|
||||
|
||||
An AI search is a single-turn AI conversation using a predefined retrieval strategy (a hybrid search of weighted keyword similarity and weighted vector similarity) and the system's default chat model. It does not involve advanced RAG strategies like knowledge graph, auto-keyword, or auto-question. The related chunks are listed below the chat model's response in descending order based on their similarity scores.
|
||||
An AI search is a single-turn AI conversation using a predefined retrieval strategy (a hybrid search of weighted keyword similarity and weighted vector similarity) and the system's default chat model. It does not involve advanced RAG strategies like knowledge graph, auto-keyword, or auto-question. The related chunks are listed below the chat model's response in descending order based on their similarity scores.
|
||||
|
||||
|
||||
|
||||
|
||||
@ -4,5 +4,8 @@
|
||||
"link": {
|
||||
"type": "generated-index",
|
||||
"description": "Chat-specific guides."
|
||||
},
|
||||
"customProps": {
|
||||
"categoryIcon": "LucideMessagesSquare"
|
||||
}
|
||||
}
|
||||
|
||||
@ -4,5 +4,8 @@
|
||||
"link": {
|
||||
"type": "generated-index",
|
||||
"description": "Best practices on chat assistant configuration."
|
||||
},
|
||||
"customProps": {
|
||||
"categoryIcon": "LucideStar"
|
||||
}
|
||||
}
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 3
|
||||
slug: /implement_deep_research
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideScanSearch
|
||||
}
|
||||
---
|
||||
|
||||
# Implement deep research
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 4
|
||||
slug: /set_chat_variables
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideVariable
|
||||
}
|
||||
---
|
||||
|
||||
# Set variables
|
||||
@ -91,7 +94,7 @@ from ragflow_sdk import RAGFlow
|
||||
rag_object = RAGFlow(api_key="<YOUR_API_KEY>", base_url="http://<YOUR_BASE_URL>:9380")
|
||||
assistant = rag_object.list_chats(name="Miss R")
|
||||
assistant = assistant[0]
|
||||
session = assistant.create_session()
|
||||
session = assistant.create_session()
|
||||
|
||||
print("\n==================== Miss R =====================\n")
|
||||
print("Hello. What can I do for you?")
|
||||
@ -99,9 +102,9 @@ print("Hello. What can I do for you?")
|
||||
while True:
|
||||
question = input("\n==================== User =====================\n> ")
|
||||
style = input("Please enter your preferred style (e.g., formal, informal, hilarious): ")
|
||||
|
||||
|
||||
print("\n==================== Miss R =====================\n")
|
||||
|
||||
|
||||
cont = ""
|
||||
for ans in session.ask(question, stream=True, style=style):
|
||||
print(ans.content[len(cont):], end='', flush=True)
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 1
|
||||
slug: /start_chat
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideBot
|
||||
}
|
||||
---
|
||||
|
||||
# Start AI chat
|
||||
@ -42,8 +45,8 @@ You start an AI conversation by creating an assistant.
|
||||
- **Rerank model** sets the reranker model to use. It is left empty by default.
|
||||
- If **Rerank model** is left empty, the hybrid score system uses keyword similarity and vector similarity, and the default weight assigned to the vector similarity component is 1-0.7=0.3.
|
||||
- If **Rerank model** is selected, the hybrid score system uses keyword similarity and reranker score, and the default weight assigned to the reranker score is 1-0.7=0.3.
|
||||
- [Cross-language search](../../references/glossary.mdx#cross-language-search): Optional
|
||||
Select one or more target languages from the dropdown menu. The system’s default chat model will then translate your query into the selected target language(s). This translation ensures accurate semantic matching across languages, allowing you to retrieve relevant results regardless of language differences.
|
||||
- [Cross-language search](../../references/glossary.mdx#cross-language-search): Optional
|
||||
Select one or more target languages from the dropdown menu. The system’s default chat model will then translate your query into the selected target language(s). This translation ensures accurate semantic matching across languages, allowing you to retrieve relevant results regardless of language differences.
|
||||
- When selecting target languages, please ensure that these languages are present in the dataset to guarantee an effective search.
|
||||
- If no target language is selected, the system will search only in the language of your query, which may cause relevant information in other languages to be missed.
|
||||
- **Variable** refers to the variables (keys) to be used in the system prompt. `{knowledge}` is a reserved variable. Click **Add** to add more variables for the system prompt.
|
||||
@ -55,23 +58,23 @@ You start an AI conversation by creating an assistant.
|
||||
4. Update Model-specific Settings:
|
||||
|
||||
- In **Model**: you select the chat model. Though you have selected the default chat model in **System Model Settings**, RAGFlow allows you to choose an alternative chat model for your dialogue.
|
||||
- **Creativity**: A shortcut to **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty** settings, indicating the freedom level of the model. From **Improvise**, **Precise**, to **Balance**, each preset configuration corresponds to a unique combination of **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty**.
|
||||
- **Creativity**: A shortcut to **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty** settings, indicating the freedom level of the model. From **Improvise**, **Precise**, to **Balance**, each preset configuration corresponds to a unique combination of **Temperature**, **Top P**, **Presence penalty**, and **Frequency penalty**.
|
||||
This parameter has three options:
|
||||
- **Improvise**: Produces more creative responses.
|
||||
- **Precise**: (Default) Produces more conservative responses.
|
||||
- **Balance**: A middle ground between **Improvise** and **Precise**.
|
||||
- **Temperature**: The randomness level of the model's output.
|
||||
- **Temperature**: The randomness level of the model's output.
|
||||
Defaults to 0.1.
|
||||
- Lower values lead to more deterministic and predictable outputs.
|
||||
- Higher values lead to more creative and varied outputs.
|
||||
- A temperature of zero results in the same output for the same prompt.
|
||||
- **Top P**: Nucleus sampling.
|
||||
- **Top P**: Nucleus sampling.
|
||||
- Reduces the likelihood of generating repetitive or unnatural text by setting a threshold *P* and restricting the sampling to tokens with a cumulative probability exceeding *P*.
|
||||
- Defaults to 0.3.
|
||||
- **Presence penalty**: Encourages the model to include a more diverse range of tokens in the response.
|
||||
- **Presence penalty**: Encourages the model to include a more diverse range of tokens in the response.
|
||||
- A higher **presence penalty** value results in the model being more likely to generate tokens not yet been included in the generated text.
|
||||
- Defaults to 0.4.
|
||||
- **Frequency penalty**: Discourages the model from repeating the same words or phrases too frequently in the generated text.
|
||||
- **Frequency penalty**: Discourages the model from repeating the same words or phrases too frequently in the generated text.
|
||||
- A higher **frequency penalty** value results in the model being more conservative in its use of repeated tokens.
|
||||
- Defaults to 0.7.
|
||||
|
||||
|
||||
@ -4,5 +4,8 @@
|
||||
"link": {
|
||||
"type": "generated-index",
|
||||
"description": "Guides on configuring a dataset."
|
||||
},
|
||||
"customProps": {
|
||||
"categoryIcon": "LucideDatabaseZap"
|
||||
}
|
||||
}
|
||||
|
||||
@ -4,5 +4,8 @@
|
||||
"link": {
|
||||
"type": "generated-index",
|
||||
"description": "Add various data sources"
|
||||
},
|
||||
"customProps": {
|
||||
"categoryIcon": "LucideServer"
|
||||
}
|
||||
}
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 3
|
||||
slug: /add_google_drive
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: SiGoogledrive
|
||||
}
|
||||
---
|
||||
|
||||
# Add Google Drive
|
||||
@ -10,9 +13,9 @@ slug: /add_google_drive
|
||||
You can either create a dedicated project for RAGFlow or use an existing
|
||||
Google Cloud external project.
|
||||
|
||||
**Steps:**
|
||||
**Steps:**
|
||||
1. Open the project creation page\
|
||||
`https://console.cloud.google.com/projectcreate`
|
||||
`https://console.cloud.google.com/projectcreate`
|
||||

|
||||
2. Select **External** as the Audience
|
||||

|
||||
@ -96,11 +99,11 @@ Navigate to the Google API Library:\
|
||||
|
||||
Enable the following APIs:
|
||||
|
||||
- Google Drive API
|
||||
- Admin SDK API
|
||||
- Google Sheets API
|
||||
- Google Drive API
|
||||
- Admin SDK API
|
||||
- Google Sheets API
|
||||
- Google Docs API
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
@ -126,7 +129,7 @@ Enable the following APIs:
|
||||

|
||||
|
||||
5. Click **Authorize with Google**
|
||||
A browser window will appear.
|
||||
A browser window will appear.
|
||||

|
||||
Click: - **Continue** - **Select All → Continue** - Authorization should
|
||||
succeed - Select **OK** to add the data source
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: -6
|
||||
slug: /auto_metadata
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideFileCodeCorner
|
||||
}
|
||||
---
|
||||
|
||||
# Auto-extract metadata
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 3
|
||||
slug: /autokeyword_autoquestion
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideSlidersHorizontal
|
||||
}
|
||||
---
|
||||
|
||||
# Auto-keyword Auto-question
|
||||
@ -20,14 +23,14 @@ Enabling this feature increases document indexing time and uses extra tokens, as
|
||||
|
||||
Auto-keyword refers to the auto-keyword generation feature of RAGFlow. It uses a chat model to generate a set of keywords or synonyms from each chunk to correct errors and enhance retrieval accuracy. This feature is implemented as a slider under **Page rank** on the **Configuration** page of your dataset.
|
||||
|
||||
**Values**:
|
||||
**Values**:
|
||||
|
||||
- 0: (Default) Disabled.
|
||||
- Between 3 and 5 (inclusive): Recommended if you have chunks of approximately 1,000 characters.
|
||||
- 30 (maximum)
|
||||
- 0: (Default) Disabled.
|
||||
- Between 3 and 5 (inclusive): Recommended if you have chunks of approximately 1,000 characters.
|
||||
- 30 (maximum)
|
||||
|
||||
:::tip NOTE
|
||||
- If your chunk size increases, you can increase the value accordingly. Please note, as the value increases, the marginal benefit decreases.
|
||||
- If your chunk size increases, you can increase the value accordingly. Please note, as the value increases, the marginal benefit decreases.
|
||||
- An Auto-keyword value must be an integer. If you set it to a non-integer, say 1.7, it will be rounded down to the nearest integer, which in this case is 1.
|
||||
:::
|
||||
|
||||
@ -37,12 +40,12 @@ Auto-question is a feature of RAGFlow that automatically generates questions fro
|
||||
|
||||
**Values**:
|
||||
|
||||
- 0: (Default) Disabled.
|
||||
- 1 or 2: Recommended if you have chunks of approximately 1,000 characters.
|
||||
- 0: (Default) Disabled.
|
||||
- 1 or 2: Recommended if you have chunks of approximately 1,000 characters.
|
||||
- 10 (maximum)
|
||||
|
||||
:::tip NOTE
|
||||
- If your chunk size increases, you can increase the value accordingly. Please note, as the value increases, the marginal benefit decreases.
|
||||
- If your chunk size increases, you can increase the value accordingly. Please note, as the value increases, the marginal benefit decreases.
|
||||
- An Auto-question value must be an integer. If you set it to a non-integer, say 1.7, it will be rounded down to the nearest integer, which in this case is 1.
|
||||
:::
|
||||
|
||||
|
||||
@ -4,5 +4,8 @@
|
||||
"link": {
|
||||
"type": "generated-index",
|
||||
"description": "Best practices on configuring a dataset."
|
||||
},
|
||||
"customProps": {
|
||||
"categoryIcon": "LucideStar"
|
||||
}
|
||||
}
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: -4
|
||||
slug: /configure_child_chunking_strategy
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideGroup
|
||||
}
|
||||
---
|
||||
|
||||
# Configure child chunking strategy
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: -10
|
||||
slug: /configure_knowledge_base
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideCog
|
||||
}
|
||||
---
|
||||
|
||||
# Configure dataset
|
||||
@ -22,7 +25,7 @@ _Each time a dataset is created, a folder with the same name is generated in the
|
||||
|
||||
## Configure dataset
|
||||
|
||||
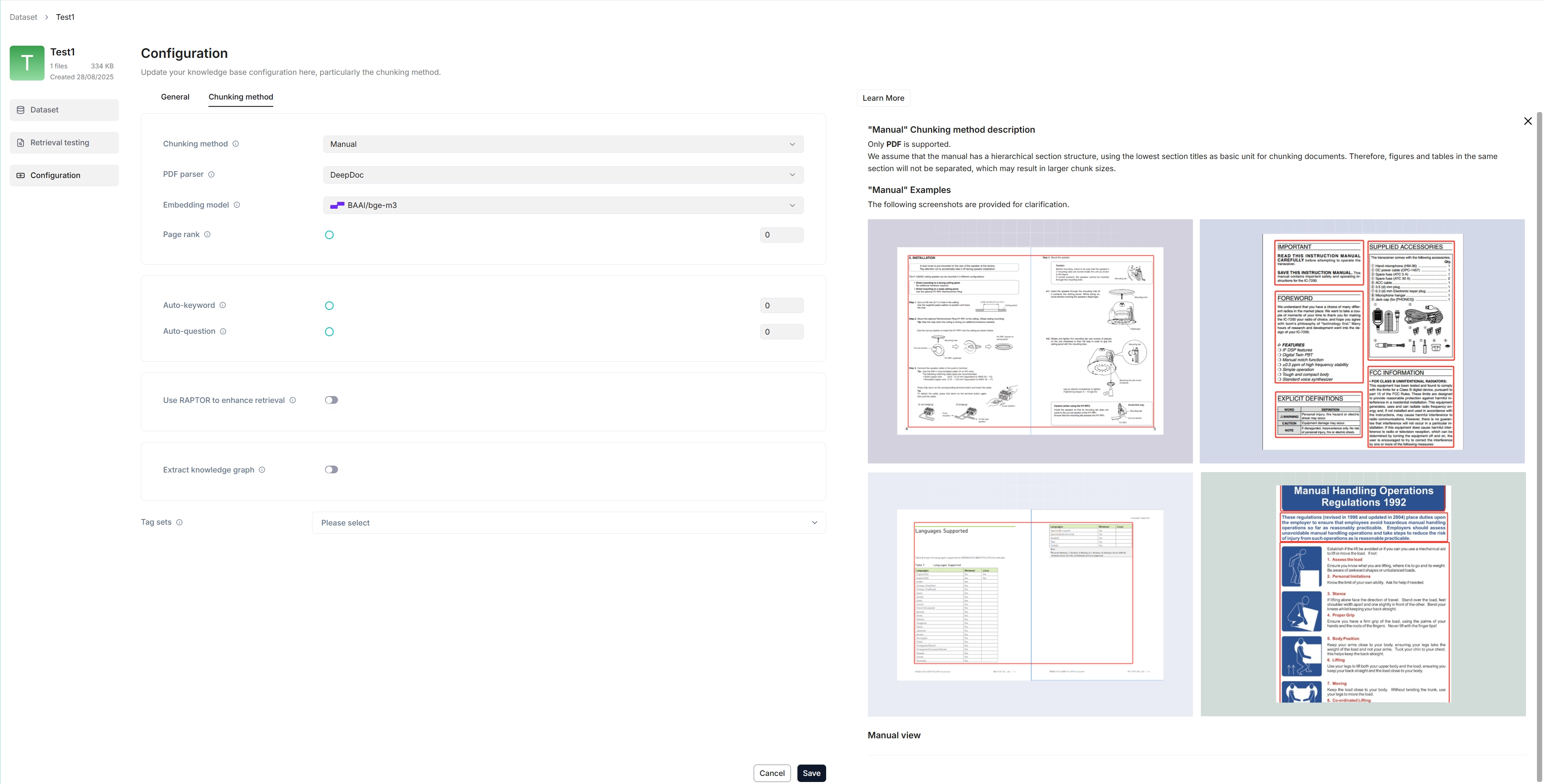
The following screenshot shows the configuration page of a dataset. A proper configuration of your dataset is crucial for future AI chats. For example, choosing the wrong embedding model or chunking method would cause unexpected semantic loss or mismatched answers in chats.
|
||||
The following screenshot shows the configuration page of a dataset. A proper configuration of your dataset is crucial for future AI chats. For example, choosing the wrong embedding model or chunking method would cause unexpected semantic loss or mismatched answers in chats.
|
||||
|
||||
|
||||
|
||||
@ -60,14 +63,14 @@ You can also change a file's chunking method on the **Files** page.
|
||||
|
||||
<details>
|
||||
<summary>From v0.21.0 onward, RAGFlow supports ingestion pipeline for customized data ingestion and cleansing workflows.</summary>
|
||||
|
||||
|
||||
To use a customized data pipeline:
|
||||
|
||||
1. On the **Agent** page, click **+ Create agent** > **Create from blank**.
|
||||
2. Select **Ingestion pipeline** and name your data pipeline in the popup, then click **Save** to show the data pipeline canvas.
|
||||
3. After updating your data pipeline, click **Save** on the top right of the canvas.
|
||||
4. Navigate to the **Configuration** page of your dataset, select **Choose pipeline** in **Ingestion pipeline**.
|
||||
|
||||
|
||||
*Your saved data pipeline will appear in the dropdown menu below.*
|
||||
|
||||
</details>
|
||||
@ -83,9 +86,9 @@ Some embedding models are optimized for specific languages, so performance may b
|
||||
### Upload file
|
||||
|
||||
- RAGFlow's File system allows you to link a file to multiple datasets, in which case each target dataset holds a reference to the file.
|
||||
- In **Knowledge Base**, you are also given the option of uploading a single file or a folder of files (bulk upload) from your local machine to a dataset, in which case the dataset holds file copies.
|
||||
- In **Knowledge Base**, you are also given the option of uploading a single file or a folder of files (bulk upload) from your local machine to a dataset, in which case the dataset holds file copies.
|
||||
|
||||
While uploading files directly to a dataset seems more convenient, we *highly* recommend uploading files to RAGFlow's File system and then linking them to the target datasets. This way, you can avoid permanently deleting files uploaded to the dataset.
|
||||
While uploading files directly to a dataset seems more convenient, we *highly* recommend uploading files to RAGFlow's File system and then linking them to the target datasets. This way, you can avoid permanently deleting files uploaded to the dataset.
|
||||
|
||||
### Parse file
|
||||
|
||||
@ -93,14 +96,14 @@ File parsing is a crucial topic in dataset configuration. The meaning of file pa
|
||||
|
||||
|
||||
|
||||
- As shown above, RAGFlow allows you to use a different chunking method for a particular file, offering flexibility beyond the default method.
|
||||
- As shown above, RAGFlow allows you to enable or disable individual files, offering finer control over dataset-based AI chats.
|
||||
- As shown above, RAGFlow allows you to use a different chunking method for a particular file, offering flexibility beyond the default method.
|
||||
- As shown above, RAGFlow allows you to enable or disable individual files, offering finer control over dataset-based AI chats.
|
||||
|
||||
### Intervene with file parsing results
|
||||
|
||||
RAGFlow features visibility and explainability, allowing you to view the chunking results and intervene where necessary. To do so:
|
||||
RAGFlow features visibility and explainability, allowing you to view the chunking results and intervene where necessary. To do so:
|
||||
|
||||
1. Click on the file that completes file parsing to view the chunking results:
|
||||
1. Click on the file that completes file parsing to view the chunking results:
|
||||
|
||||
_You are taken to the **Chunk** page:_
|
||||
|
||||
@ -113,7 +116,7 @@ RAGFlow features visibility and explainability, allowing you to view the chunkin
|
||||
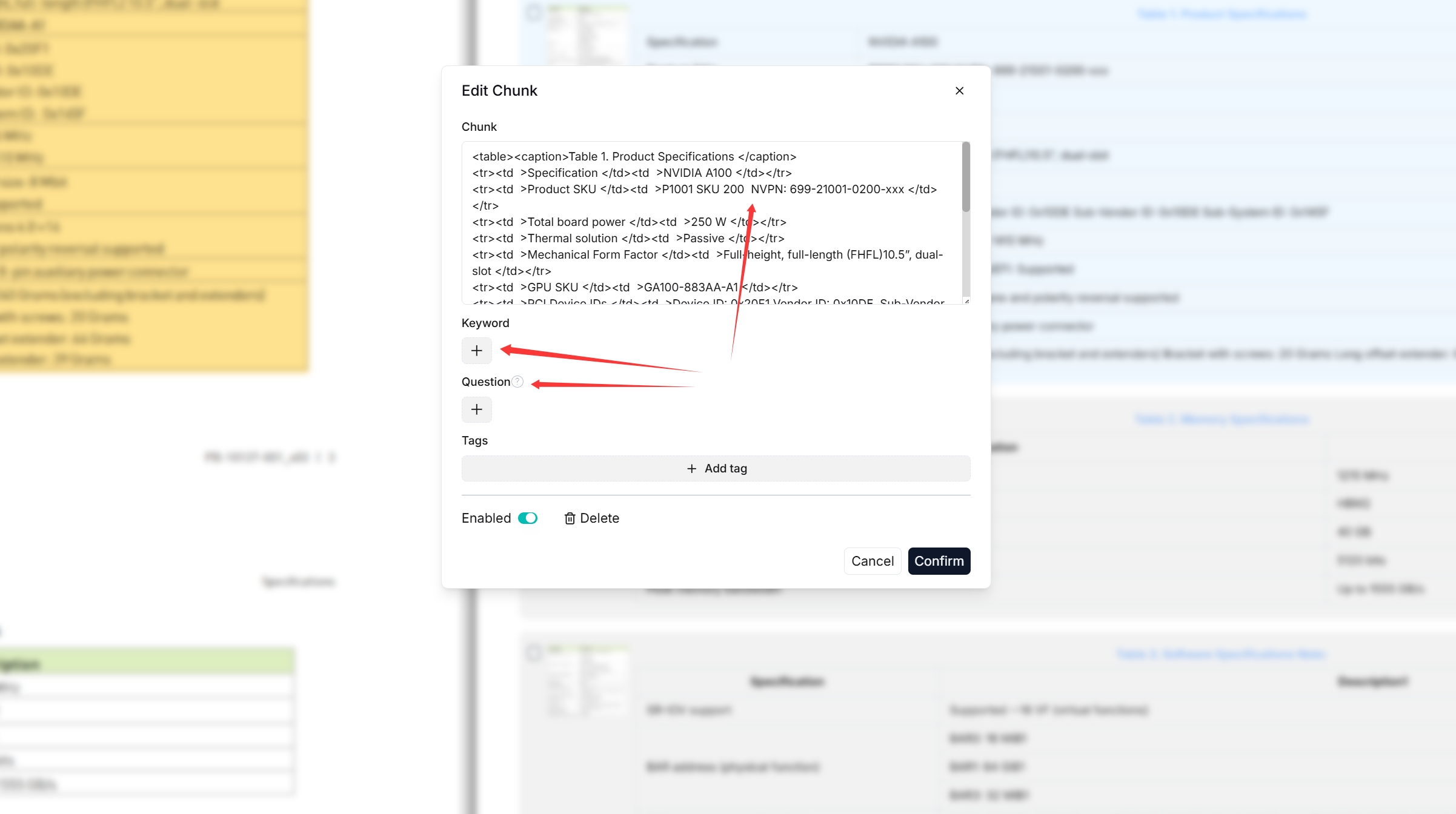
|
||||
|
||||
:::caution NOTE
|
||||
You can add keywords to a file chunk to increase its ranking for queries containing those keywords. This action increases its keyword weight and can improve its position in search list.
|
||||
You can add keywords to a file chunk to increase its ranking for queries containing those keywords. This action increases its keyword weight and can improve its position in search list.
|
||||
:::
|
||||
|
||||
4. In Retrieval testing, ask a quick question in **Test text** to double-check if your configurations work:
|
||||
@ -141,7 +144,7 @@ As of RAGFlow v0.23.1, the search feature is still in a rudimentary form, suppor
|
||||
|
||||
You are allowed to delete a dataset. Hover your mouse over the three dot of the intended dataset card and the **Delete** option appears. Once you delete a dataset, the associated folder under **root/.knowledge** directory is AUTOMATICALLY REMOVED. The consequence is:
|
||||
|
||||
- The files uploaded directly to the dataset are gone;
|
||||
- The file references, which you created from within RAGFlow's File system, are gone, but the associated files still exist.
|
||||
- The files uploaded directly to the dataset are gone;
|
||||
- The file references, which you created from within RAGFlow's File system, are gone, but the associated files still exist.
|
||||
|
||||

|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 8
|
||||
slug: /construct_knowledge_graph
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideWandSparkles
|
||||
}
|
||||
---
|
||||
|
||||
# Construct knowledge graph
|
||||
@ -63,7 +66,7 @@ In a knowledge graph, a community is a cluster of entities linked by relationshi
|
||||
## Quickstart
|
||||
|
||||
1. Navigate to the **Configuration** page of your dataset and update:
|
||||
|
||||
|
||||
- Entity types: *Required* - Specifies the entity types in the knowledge graph to generate. You don't have to stick with the default, but you need to customize them for your documents.
|
||||
- Method: *Optional*
|
||||
- Entity resolution: *Optional*
|
||||
@ -74,12 +77,12 @@ In a knowledge graph, a community is a cluster of entities linked by relationshi
|
||||
|
||||
*You can click the pause button in the dropdown to halt the build process when necessary.*
|
||||
|
||||
3. Go back to the **Configuration** page:
|
||||
|
||||
3. Go back to the **Configuration** page:
|
||||
|
||||
*Once a knowledge graph is generated, the **Knowledge graph** field changes from `Not generated` to `Generated at a specific timestamp`. You can delete it by clicking the recycle bin button to the right of the field.*
|
||||
|
||||
4. To use the created knowledge graph, do either of the following:
|
||||
|
||||
|
||||
- In the **Chat setting** panel of your chat app, switch on the **Use knowledge graph** toggle.
|
||||
- If you are using an agent, click the **Retrieval** agent component to specify the dataset(s) and switch on the **Use knowledge graph** toggle.
|
||||
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 4
|
||||
slug: /enable_excel2html
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideToggleRight
|
||||
}
|
||||
---
|
||||
|
||||
# Enable Excel2HTML
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 7
|
||||
slug: /enable_raptor
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideNetwork
|
||||
}
|
||||
---
|
||||
|
||||
# Enable RAPTOR
|
||||
@ -76,7 +79,7 @@ A random seed. Click **+** to change the seed value.
|
||||
## Quickstart
|
||||
|
||||
1. Navigate to the **Configuration** page of your dataset and update:
|
||||
|
||||
|
||||
- Prompt: *Optional* - We recommend that you keep it as-is until you understand the mechanism behind.
|
||||
- Max token: *Optional*
|
||||
- Threshold: *Optional*
|
||||
@ -86,8 +89,8 @@ A random seed. Click **+** to change the seed value.
|
||||
|
||||
*You can click the pause button in the dropdown to halt the build process when necessary.*
|
||||
|
||||
3. Go back to the **Configuration** page:
|
||||
|
||||
3. Go back to the **Configuration** page:
|
||||
|
||||
*The **RAPTOR** field changes from `Not generated` to `Generated at a specific timestamp` when a RAPTOR hierarchical tree structure is generated. You can delete it by clicking the recycle bin button to the right of the field.*
|
||||
|
||||
4. Once a RAPTOR hierarchical tree structure is generated, your chat assistant and **Retrieval** agent component will use it for retrieval as a default.
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 4
|
||||
slug: /enable_table_of_contents
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideTableOfContents
|
||||
}
|
||||
---
|
||||
|
||||
# Extract table of contents
|
||||
@ -28,7 +31,7 @@ The system's default chat model is used to summarize clustered content. Before p
|
||||
2. Enable **TOC Enhance**.
|
||||
|
||||
3. To use this technique during retrieval, do either of the following:
|
||||
|
||||
|
||||
- In the **Chat setting** panel of your chat app, switch on the **TOC Enhance** toggle.
|
||||
- If you are using an agent, click the **Retrieval** agent component to specify the dataset(s) and switch on the **TOC Enhance** toggle.
|
||||
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: -5
|
||||
slug: /manage_metadata
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideCode
|
||||
}
|
||||
---
|
||||
|
||||
# Manage metadata
|
||||
@ -19,7 +22,7 @@ From v0.23.0 onwards, RAGFlow allows you to manage metadata both at the dataset
|
||||
|
||||
|
||||
|
||||
2. On the **Manage Metadata** page, you can do either of the following:
|
||||
2. On the **Manage Metadata** page, you can do either of the following:
|
||||
- Edit Values: You can modify existing values. If you rename two values to be identical, they will be automatically merged.
|
||||
- Delete: You can delete specific values or entire fields. These changes will apply to all associated files.
|
||||
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 10
|
||||
slug: /run_retrieval_test
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideTextSearch
|
||||
}
|
||||
---
|
||||
|
||||
# Run retrieval test
|
||||
@ -53,7 +56,7 @@ The switch is disabled by default. When enabled, RAGFlow performs the following
|
||||
3. Find similar entities and their N-hop relationships from the graph using the embeddings of the extracted query entities.
|
||||
4. Retrieve similar relationships from the graph using the query embedding.
|
||||
5. Rank these retrieved entities and relationships by multiplying each one's PageRank value with its similarity score to the query, returning the top n as the final retrieval.
|
||||
6. Retrieve the report for the community involving the most entities in the final retrieval.
|
||||
6. Retrieve the report for the community involving the most entities in the final retrieval.
|
||||
*The retrieved entity descriptions, relationship descriptions, and the top 1 community report are sent to the LLM for content generation.*
|
||||
|
||||
:::danger IMPORTANT
|
||||
@ -78,10 +81,10 @@ This field is where you put in your testing query.
|
||||
1. Navigate to the **Retrieval testing** page of your dataset, enter your query in **Test text**, and click **Testing** to run the test.
|
||||
2. If the results are unsatisfactory, tune the options listed in the Configuration section and rerun the test.
|
||||
|
||||
*The following is a screenshot of a retrieval test conducted without using knowledge graph. It demonstrates a hybrid search combining weighted keyword similarity and weighted vector cosine similarity. The overall hybrid similarity score is 28.56, calculated as 25.17 (term similarity score) x 0.7 + 36.49 (vector similarity score) x 0.3:*
|
||||
*The following is a screenshot of a retrieval test conducted without using knowledge graph. It demonstrates a hybrid search combining weighted keyword similarity and weighted vector cosine similarity. The overall hybrid similarity score is 28.56, calculated as 25.17 (term similarity score) x 0.7 + 36.49 (vector similarity score) x 0.3:*
|
||||

|
||||
|
||||
*The following is a screenshot of a retrieval test conducted using a knowledge graph. It shows that only vector similarity is used for knowledge graph-generated chunks:*
|
||||
*The following is a screenshot of a retrieval test conducted using a knowledge graph. It shows that only vector similarity is used for knowledge graph-generated chunks:*
|
||||

|
||||
|
||||
:::caution WARNING
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: -3
|
||||
slug: /select_pdf_parser
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideFileText
|
||||
}
|
||||
---
|
||||
|
||||
# Select PDF parser
|
||||
@ -54,12 +57,12 @@ Starting from v0.22.0, RAGFlow includes MinerU (≥ 2.6.3) as an optional PDF p
|
||||
- `"vlm-mlx-engine"`
|
||||
- `"vlm-vllm-async-engine"`
|
||||
- `"vlm-lmdeploy-engine"`.
|
||||
- `MINERU_SERVER_URL`: (optional) The downstream vLLM HTTP server (e.g., `http://vllm-host:30000`). Applicable when `MINERU_BACKEND` is set to `"vlm-http-client"`.
|
||||
- `MINERU_SERVER_URL`: (optional) The downstream vLLM HTTP server (e.g., `http://vllm-host:30000`). Applicable when `MINERU_BACKEND` is set to `"vlm-http-client"`.
|
||||
- `MINERU_OUTPUT_DIR`: (optional) The local directory for holding the outputs of the MinerU API service (zip/JSON) before ingestion.
|
||||
- `MINERU_DELETE_OUTPUT`: Whether to delete temporary output when a temporary directory is used:
|
||||
- `1`: Delete.
|
||||
- `0`: Retain.
|
||||
3. In the web UI, navigate to your dataset's **Configuration** page and find the **Ingestion pipeline** section:
|
||||
3. In the web UI, navigate to your dataset's **Configuration** page and find the **Ingestion pipeline** section:
|
||||
- If you decide to use a chunking method from the **Built-in** dropdown, ensure it supports PDF parsing, then select **MinerU** from the **PDF parser** dropdown.
|
||||
- If you use a custom ingestion pipeline instead, select **MinerU** in the **PDF parser** section of the **Parser** component.
|
||||
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: -8
|
||||
slug: /set_context_window
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideListChevronsUpDown
|
||||
}
|
||||
---
|
||||
|
||||
# Set context window size
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: -7
|
||||
slug: /set_metadata
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideCode
|
||||
}
|
||||
---
|
||||
|
||||
# Set metadata
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: -2
|
||||
slug: /set_page_rank
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideStickyNote
|
||||
}
|
||||
---
|
||||
|
||||
# Set page rank
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 6
|
||||
slug: /use_tag_sets
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideTags
|
||||
}
|
||||
---
|
||||
|
||||
# Use tag set
|
||||
@ -43,10 +46,10 @@ A tag set is *not* involved in document indexing or retrieval. Do not specify a
|
||||
|
||||
1. Click **+ Create dataset** to create a dataset.
|
||||
2. Navigate to the **Configuration** page of the created dataset, select **Built-in** in **Ingestion pipeline**, then choose **Tag** as the default chunking method from the **Built-in** drop-down menu.
|
||||
3. Go back to the **Files** page and upload and parse your table file in XLSX, CSV, or TXT formats.
|
||||
_A tag cloud appears under the **Tag view** section, indicating the tag set is created:_
|
||||
3. Go back to the **Files** page and upload and parse your table file in XLSX, CSV, or TXT formats.
|
||||
_A tag cloud appears under the **Tag view** section, indicating the tag set is created:_
|
||||

|
||||
4. Click the **Table** tab to view the tag frequency table:
|
||||
4. Click the **Table** tab to view the tag frequency table:
|
||||

|
||||
|
||||
## 2. Tag chunks
|
||||
@ -60,12 +63,12 @@ Once a tag set is created, you can apply it to your dataset:
|
||||
If the tag set is missing from the dropdown, check that it has been created or configured correctly.
|
||||
:::
|
||||
|
||||
3. Re-parse your documents to start the auto-tagging process.
|
||||
3. Re-parse your documents to start the auto-tagging process.
|
||||
_In an AI chat scenario using auto-tagged datasets, each query will be tagged using the corresponding tag set(s) and chunks with these tags will have a higher chance to be retrieved._
|
||||
|
||||
## 3. Update tag set
|
||||
|
||||
Creating a tag set is *not* for once and for all. Oftentimes, you may find it necessary to update or delete existing tags or add new entries.
|
||||
Creating a tag set is *not* for once and for all. Oftentimes, you may find it necessary to update or delete existing tags or add new entries.
|
||||
|
||||
- You can update the existing tag set in the tag frequency table.
|
||||
- To add new entries, you can add and parse new table files in XLSX, CSV, or TXT formats.
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 6
|
||||
slug: /manage_files
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideFolderDot
|
||||
}
|
||||
---
|
||||
|
||||
# Files
|
||||
@ -13,7 +16,7 @@ Compared to uploading files directly to various datasets, uploading them to RAGF
|
||||
|
||||
## Create folder
|
||||
|
||||
RAGFlow's file management allows you to establish your file system with nested folder structures. To create a folder in the root directory of RAGFlow:
|
||||
RAGFlow's file management allows you to establish your file system with nested folder structures. To create a folder in the root directory of RAGFlow:
|
||||
|
||||

|
||||
|
||||
@ -23,7 +26,7 @@ Each dataset in RAGFlow has a corresponding folder under the **root/.knowledgeba
|
||||
|
||||
## Upload file
|
||||
|
||||
RAGFlow's file management supports file uploads from your local machine, allowing both individual and bulk uploads:
|
||||
RAGFlow's file management supports file uploads from your local machine, allowing both individual and bulk uploads:
|
||||
|
||||

|
||||
|
||||
@ -45,7 +48,7 @@ RAGFlow's file management allows you to *link* an uploaded file to multiple data
|
||||
|
||||

|
||||
|
||||
You can link your file to one dataset or multiple datasets at one time:
|
||||
You can link your file to one dataset or multiple datasets at one time:
|
||||
|
||||

|
||||
|
||||
@ -68,9 +71,9 @@ RAGFlow's file management allows you to rename a file or folder:
|
||||
|
||||
## Delete files or folders
|
||||
|
||||
RAGFlow's file management allows you to delete files or folders individually or in bulk.
|
||||
RAGFlow's file management allows you to delete files or folders individually or in bulk.
|
||||
|
||||
To delete a file or folder:
|
||||
To delete a file or folder:
|
||||
|
||||

|
||||
|
||||
@ -78,7 +81,7 @@ To bulk delete files or folders:
|
||||
|
||||

|
||||
|
||||
> - You are not allowed to delete the **root/.knowledgebase** folder.
|
||||
> - You are not allowed to delete the **root/.knowledgebase** folder.
|
||||
> - Deleting files that have been linked to datasets will **AUTOMATICALLY REMOVE** all associated file references across the datasets.
|
||||
|
||||
## Download uploaded file
|
||||
@ -87,4 +90,4 @@ RAGFlow's file management allows you to download an uploaded file:
|
||||
|
||||

|
||||
|
||||
> As of RAGFlow v0.23.1, bulk download is not supported, nor can you download an entire folder.
|
||||
> As of RAGFlow v0.23.1, bulk download is not supported, nor can you download an entire folder.
|
||||
|
||||
@ -4,5 +4,8 @@
|
||||
"link": {
|
||||
"type": "generated-index",
|
||||
"description": "RAGFlow migration guide"
|
||||
},
|
||||
"customProps": {
|
||||
"categoryIcon": "LucideArrowRightLeft"
|
||||
}
|
||||
}
|
||||
|
||||
@ -4,5 +4,8 @@
|
||||
"link": {
|
||||
"type": "generated-index",
|
||||
"description": "Guides on model settings."
|
||||
},
|
||||
"customProps": {
|
||||
"categoryIcon": "LucideBox"
|
||||
}
|
||||
}
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 2
|
||||
slug: /deploy_local_llm
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideMonitorCog
|
||||
}
|
||||
---
|
||||
|
||||
# Deploy local models
|
||||
@ -53,9 +56,9 @@ $ sudo docker exec ollama ollama pull llama3.2
|
||||
```
|
||||
|
||||
```bash
|
||||
$ sudo docker exec ollama ollama pull bge-m3
|
||||
> pulling daec91ffb5dd... 100% ▕████████████████▏ 1.2 GB
|
||||
> success
|
||||
$ sudo docker exec ollama ollama pull bge-m3
|
||||
> pulling daec91ffb5dd... 100% ▕████████████████▏ 1.2 GB
|
||||
> success
|
||||
```
|
||||
|
||||
### 2. Find Ollama URL and ensure it is accessible
|
||||
@ -105,7 +108,7 @@ Max retries exceeded with url: /api/chat (Caused by NewConnectionError('<urllib3
|
||||
### 5. Update System Model Settings
|
||||
|
||||
Click on your logo **>** **Model providers** **>** **System Model Settings** to update your model:
|
||||
|
||||
|
||||
- *You should now be able to find **llama3.2** from the dropdown list under **Chat model**, and **bge-m3** from the dropdown list under **Embedding model**.*
|
||||
|
||||
### 6. Update Chat Configuration
|
||||
@ -125,7 +128,7 @@ To deploy a local model, e.g., **Mistral**, using Xinference:
|
||||
|
||||
### 1. Check firewall settings
|
||||
|
||||
Ensure that your host machine's firewall allows inbound connections on port 9997.
|
||||
Ensure that your host machine's firewall allows inbound connections on port 9997.
|
||||
|
||||
### 2. Start an Xinference instance
|
||||
|
||||
@ -148,13 +151,13 @@ In RAGFlow, click on your logo on the top right of the page **>** **Model provid
|
||||
|
||||
### 5. Complete basic Xinference settings
|
||||
|
||||
Enter an accessible base URL, such as `http://<your-xinference-endpoint-domain>:9997/v1`.
|
||||
Enter an accessible base URL, such as `http://<your-xinference-endpoint-domain>:9997/v1`.
|
||||
> For rerank model, please use the `http://<your-xinference-endpoint-domain>:9997/v1/rerank` as the base URL.
|
||||
|
||||
### 6. Update System Model Settings
|
||||
|
||||
Click on your logo **>** **Model providers** **>** **System Model Settings** to update your model.
|
||||
|
||||
|
||||
*You should now be able to find **mistral** from the dropdown list under **Chat model**.*
|
||||
|
||||
### 7. Update Chat Configuration
|
||||
@ -170,7 +173,7 @@ To deploy a local model, e.g., **Qwen2**, using IPEX-LLM-accelerated Ollama:
|
||||
### 1. Check firewall settings
|
||||
|
||||
Ensure that your host machine's firewall allows inbound connections on port 11434. For example:
|
||||
|
||||
|
||||
```bash
|
||||
sudo ufw allow 11434/tcp
|
||||
```
|
||||
@ -179,7 +182,7 @@ sudo ufw allow 11434/tcp
|
||||
|
||||
#### 2.1 Install IPEX-LLM for Ollama
|
||||
|
||||
:::tip NOTE
|
||||
:::tip NOTE
|
||||
IPEX-LLM's supports Ollama on Linux and Windows systems.
|
||||
:::
|
||||
|
||||
@ -191,7 +194,7 @@ For detailed information about installing IPEX-LLM for Ollama, see [Run llama.cp
|
||||
|
||||
#### 2.2 Initialize Ollama
|
||||
|
||||
1. Activate the `llm-cpp` Conda environment and initialize Ollama:
|
||||
1. Activate the `llm-cpp` Conda environment and initialize Ollama:
|
||||
|
||||
<Tabs
|
||||
defaultValue="linux"
|
||||
@ -200,7 +203,7 @@ For detailed information about installing IPEX-LLM for Ollama, see [Run llama.cp
|
||||
{label: 'Windows', value: 'windows'},
|
||||
]}>
|
||||
<TabItem value="linux">
|
||||
|
||||
|
||||
```bash
|
||||
conda activate llm-cpp
|
||||
init-ollama
|
||||
@ -218,7 +221,7 @@ For detailed information about installing IPEX-LLM for Ollama, see [Run llama.cp
|
||||
</Tabs>
|
||||
|
||||
2. If the installed `ipex-llm[cpp]` requires an upgrade to the Ollama binary files, remove the old binary files and reinitialize Ollama using `init-ollama` (Linux) or `init-ollama.bat` (Windows).
|
||||
|
||||
|
||||
*A symbolic link to Ollama appears in your current directory, and you can use this executable file following standard Ollama commands.*
|
||||
|
||||
#### 2.3 Launch Ollama service
|
||||
@ -226,7 +229,7 @@ For detailed information about installing IPEX-LLM for Ollama, see [Run llama.cp
|
||||
1. Set the environment variable `OLLAMA_NUM_GPU` to `999` to ensure that all layers of your model run on the Intel GPU; otherwise, some layers may default to CPU.
|
||||
2. For optimal performance on Intel Arc™ A-Series Graphics with Linux OS (Kernel 6.2), set the following environment variable before launching the Ollama service:
|
||||
|
||||
```bash
|
||||
```bash
|
||||
export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
|
||||
```
|
||||
3. Launch the Ollama service:
|
||||
@ -314,12 +317,12 @@ To enable IPEX-LLM accelerated Ollama in RAGFlow, you must also complete the con
|
||||
3. [Update System Model Settings](#6-update-system-model-settings)
|
||||
4. [Update Chat Configuration](#7-update-chat-configuration)
|
||||
|
||||
### 5. Deploy VLLM
|
||||
### 5. Deploy VLLM
|
||||
|
||||
ubuntu 22.04/24.04
|
||||
|
||||
```bash
|
||||
pip install vllm
|
||||
pip install vllm
|
||||
```
|
||||
### 5.1 RUN VLLM WITH BEST PRACTISE
|
||||
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 1
|
||||
slug: /llm_api_key_setup
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideKey
|
||||
}
|
||||
---
|
||||
|
||||
# Configure model API key
|
||||
@ -30,7 +33,7 @@ You have two options for configuring your model API key:
|
||||
- Update `api_key` with yours.
|
||||
- Update `base_url` if you use a proxy to connect to the remote service.
|
||||
3. Reboot your system for your changes to take effect.
|
||||
4. Log into RAGFlow.
|
||||
4. Log into RAGFlow.
|
||||
_After logging into RAGFlow, you will find your chosen model appears under **Added models** on the **Model providers** page._
|
||||
|
||||
### Configure model API key after logging into RAGFlow
|
||||
|
||||
@ -4,5 +4,8 @@
|
||||
"link": {
|
||||
"type": "generated-index",
|
||||
"description": "Team-specific guides."
|
||||
},
|
||||
"customProps": {
|
||||
"categoryIcon": "LucideUsers"
|
||||
}
|
||||
}
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 3
|
||||
slug: /join_or_leave_team
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideLogOut
|
||||
}
|
||||
---
|
||||
|
||||
# Join or leave a team
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 2
|
||||
slug: /manage_team_members
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideUserCog
|
||||
}
|
||||
---
|
||||
|
||||
# Manage team members
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 6
|
||||
slug: /share_agent
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideShare2
|
||||
}
|
||||
---
|
||||
|
||||
# Share Agent
|
||||
@ -11,7 +14,7 @@ Share an Agent with your team members.
|
||||
|
||||
When ready, you may share your Agents with your team members so that they can use them. Please note that your Agents are not shared automatically; you must manually enable sharing by selecting the corresponding **Permissions** radio button:
|
||||
|
||||
1. Click the intended Agent to open its editing canvas.
|
||||
1. Click the intended Agent to open its editing canvas.
|
||||
2. Click **Management** > **Settings** to show the **Agent settings** dialogue.
|
||||
3. Change **Permissions** from **Only me** to **Team**.
|
||||
4. Click **Save** to apply your changes.
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 5
|
||||
slug: /share_chat_assistant
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideShare2
|
||||
}
|
||||
---
|
||||
|
||||
# Share chat assistant
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 4
|
||||
slug: /share_datasets
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideShare2
|
||||
}
|
||||
---
|
||||
|
||||
# Share dataset
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 7
|
||||
slug: /share_model
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideShare2
|
||||
}
|
||||
---
|
||||
|
||||
# Share models
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 9
|
||||
slug: /tracing
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideLocateFixed
|
||||
}
|
||||
---
|
||||
|
||||
# Tracing
|
||||
@ -15,10 +18,10 @@ This document is contributed by our community contributor [jannikmaierhoefer](ht
|
||||
|
||||
RAGFlow ships with a built-in [Langfuse](https://langfuse.com) integration so that you can **inspect and debug every retrieval and generation step** of your RAG pipelines in near real-time.
|
||||
|
||||
Langfuse stores traces, spans and prompt payloads in a purpose-built observability backend and offers filtering and visualisations on top.
|
||||
Langfuse stores traces, spans and prompt payloads in a purpose-built observability backend and offers filtering and visualisations on top.
|
||||
|
||||
:::info NOTE
|
||||
• RAGFlow **≥ 0.18.0** (contains the Langfuse connector)
|
||||
• RAGFlow **≥ 0.18.0** (contains the Langfuse connector)
|
||||
• A Langfuse workspace (cloud or self-hosted) with a _Project Public Key_ and _Secret Key_
|
||||
:::
|
||||
|
||||
@ -26,9 +29,9 @@ Langfuse stores traces, spans and prompt payloads in a purpose-built observabili
|
||||
|
||||
## 1. Collect your Langfuse credentials
|
||||
|
||||
1. Sign in to your Langfuse dashboard.
|
||||
2. Open **Settings ▸ Projects** and either create a new project or select an existing one.
|
||||
3. Copy the **Public Key** and **Secret Key**.
|
||||
1. Sign in to your Langfuse dashboard.
|
||||
2. Open **Settings ▸ Projects** and either create a new project or select an existing one.
|
||||
3. Copy the **Public Key** and **Secret Key**.
|
||||
4. Note the Langfuse **host** (e.g. `https://cloud.langfuse.com`). Use the base URL of your own installation if you self-host.
|
||||
|
||||
> The keys are _project-scoped_: one pair of keys is enough for all environments that should write into the same project.
|
||||
@ -39,10 +42,10 @@ Langfuse stores traces, spans and prompt payloads in a purpose-built observabili
|
||||
|
||||
RAGFlow stores the credentials _per tenant_. You can configure them either via the web UI or the HTTP API.
|
||||
|
||||
1. Log in to RAGFlow and click your avatar in the top-right corner.
|
||||
2. Select **API ▸ Scroll down to the bottom ▸ Langfuse Configuration**.
|
||||
3. Fill in you Langfuse **Host**, **Public Key** and **Secret Key**.
|
||||
4. Click **Save**.
|
||||
1. Log in to RAGFlow and click your avatar in the top-right corner.
|
||||
2. Select **API ▸ Scroll down to the bottom ▸ Langfuse Configuration**.
|
||||
3. Fill in you Langfuse **Host**, **Public Key** and **Secret Key**.
|
||||
4. Click **Save**.
|
||||
|
||||
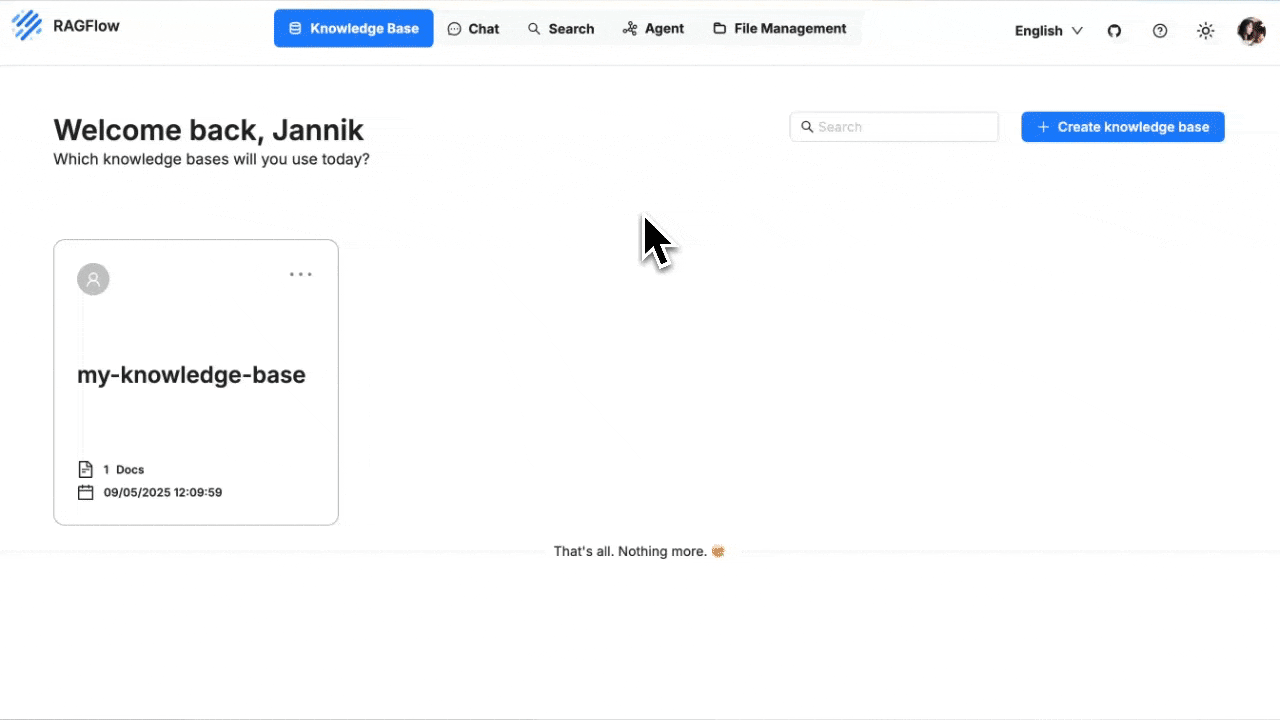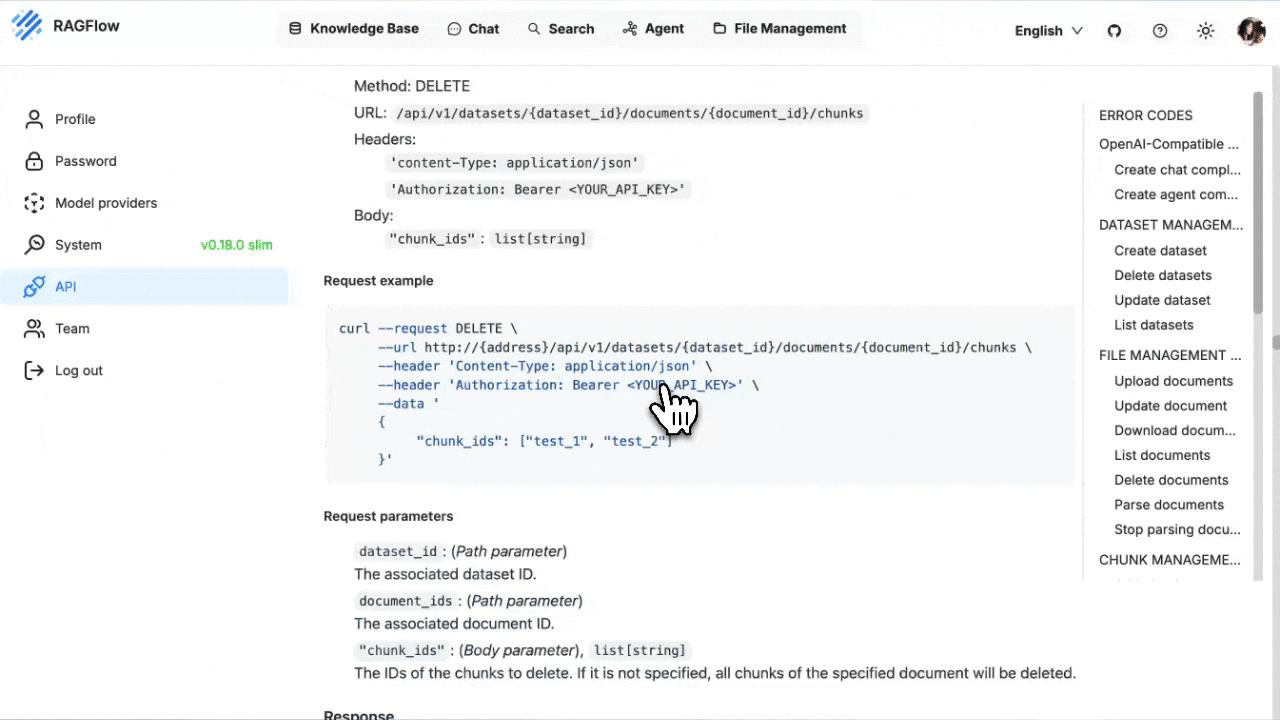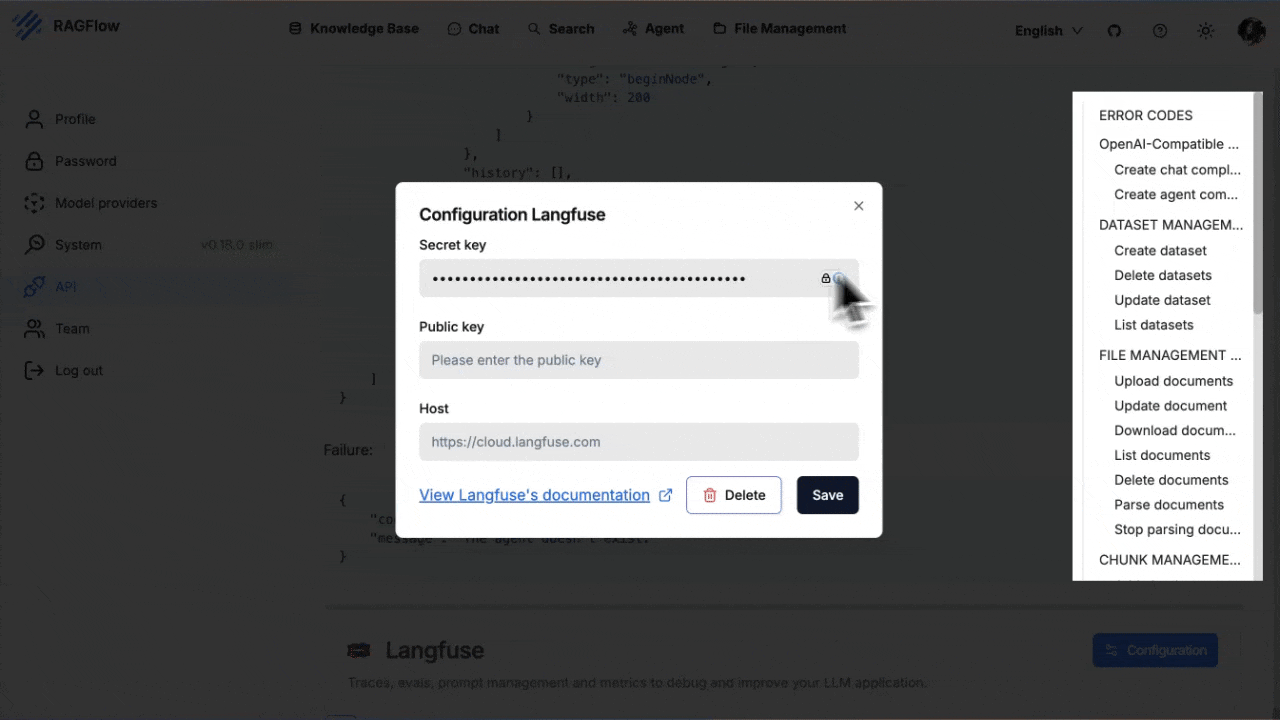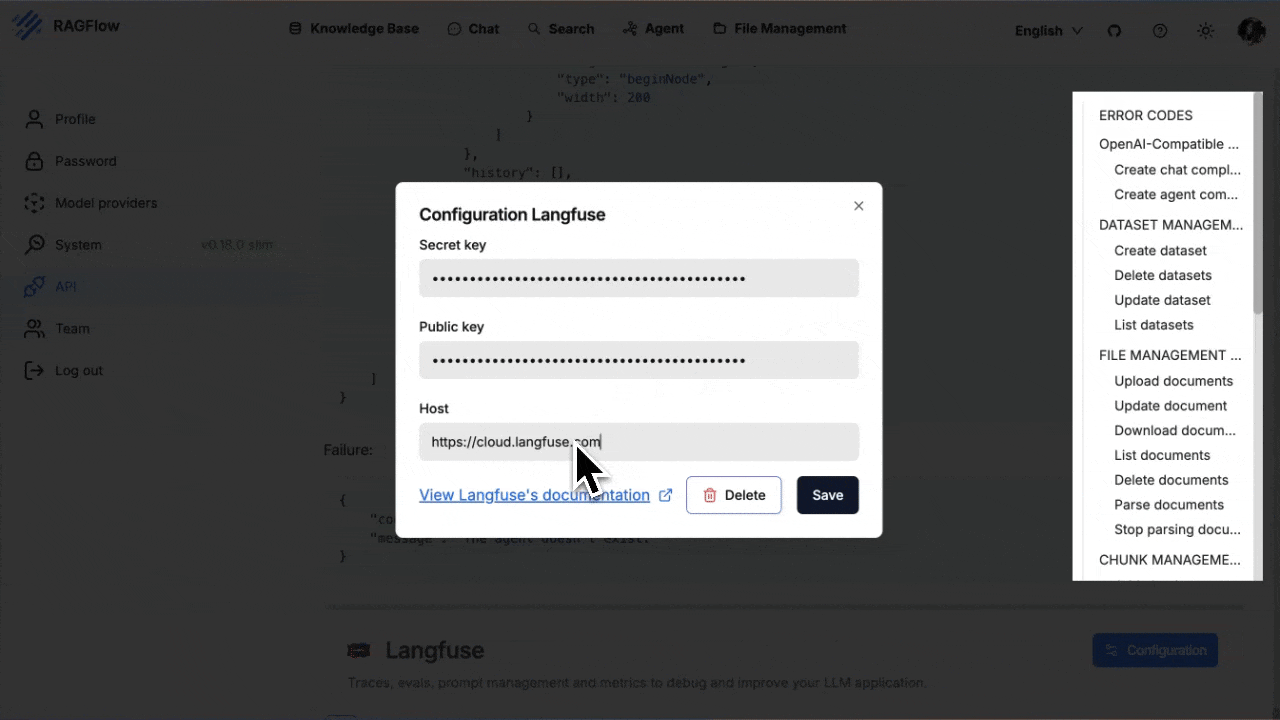
|
||||
|
||||
@ -52,14 +55,14 @@ Once saved, RAGFlow starts emitting traces automatically – no code change requ
|
||||
|
||||
## 3. Run a pipeline and watch the traces
|
||||
|
||||
1. Execute any chat or retrieval pipeline in RAGFlow (e.g. the Quickstart demo).
|
||||
2. Open your Langfuse project ▸ **Traces**.
|
||||
1. Execute any chat or retrieval pipeline in RAGFlow (e.g. the Quickstart demo).
|
||||
2. Open your Langfuse project ▸ **Traces**.
|
||||
3. Filter by **name ~ `ragflow-*`** (RAGFlow prefixes each trace with `ragflow-`).
|
||||
|
||||
For every user request you will see:
|
||||
|
||||
• a **trace** representing the overall request
|
||||
• **spans** for retrieval, ranking and generation steps
|
||||
• a **trace** representing the overall request
|
||||
• **spans** for retrieval, ranking and generation steps
|
||||
• the complete **prompts**, **retrieved documents** and **LLM responses** as metadata
|
||||
|
||||
|
||||
|
||||
@ -1,6 +1,9 @@
|
||||
---
|
||||
sidebar_position: 11
|
||||
slug: /upgrade_ragflow
|
||||
sidebar_custom_props: {
|
||||
categoryIcon: LucideArrowBigUpDash
|
||||
}
|
||||
---
|
||||
|
||||
# Upgrading
|
||||
|
||||
Reference in New Issue
Block a user